

Python培训
400-996-5531
400-996-5531
Web爬虫能自动抽取数据,并以人们容易理解的方式展现。本文章将举个金融市场的例子,但是Web爬虫能做的远不止于此。
如果你是一个狂热的投资者,当你需要的股票价格跨多个网站,那获取每天的股票价格是相当痛苦。本文通过创建一个Web爬虫自动从互联网上检索股指数据。
开始
我们将使用Python和BeautifulSoup编写爬虫:
对于Mac用户,Python已预装好。打开终端,输入python —version,你回看到Python版本是2.7.x;
对于Windows用户,请按官方文档安装Python
接下来使用pip安装BeautifulSoup库,在terminal中执行:
easy_install pip
pip install BeautifulSoup4
Note:如果执行以上命令失败,请尝试加上sudo再次执行。
基础知识
在看代码之前,先理解一下HTML网页基本知识和爬取规则。
HTML标签
如果你已经熟悉HTML标签,可以跳过此部分。
<!DOCTYPE html> <html>
<head>
</head>
<body>
<h1> First Scraping </h1>
<p> Hello World </p>
<body></html>
上面是HTML网页基本的语法,网页中的每个代表一个功能块:
<!DOCTYPE html>:HTML文档必须以<!DOCTYPE html>标签为起点;
HTML文档包含在<html> 和</html>标签之间;
HTML文档的元数据和脚本声明放在<head> 和 </head>标签之间;
HTML文档的正文部分放在 <body> 和 </body>标签内;
<h1> 到 <h6>标签定义标题;
<p> 标签定义段落;
其它常用的标签有,<a> :超链接,<table> :表格;<tr> 表格的行,<td>表格的列。
有时,HTML标签也带有 id 或者 class 属性。 id 属性是指定HTML标签的唯一id,其在HTML文档内取值唯一。 class 属性是表示同一类HTML标签。我们可以使用两个属性进行数据定位。
W3Schools上可以学到更多关于HTML tag,id和class的知识。
爬取规则
爬取网站的第一步是,阅读网站的爬取协议或者声明。一般情况,爬取的数据不能用于商业目的。
不能太频繁的请求网站数据,不然会被列入黑名单。最好能让你的程序模拟人的行为。一般设为每秒访问一个页面为最佳。
网站的布局会随时改变,确保改写你的代码能重新爬取该网页。
检查(Inspect)网页
下面拿Bloomberg Quote网站举例:
当前炒股非常火,假设某个炒股者关注股票市场,想得到股指(S&P 500)名字和价格。首先在浏览器打开该网页,使用浏览器的检查器(inspector)来检查网页。
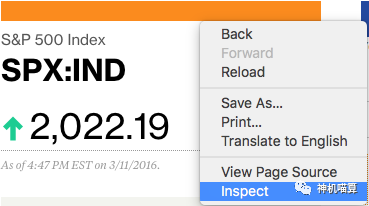
鼠标悬停在价格的位置,你会看到价格周围蓝色的方框。当点击它时,相关的网页在浏览器控制台上显示被选中。
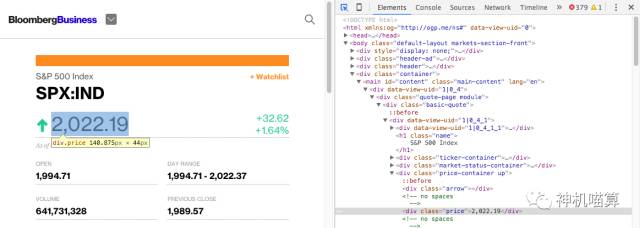
上面的结果显示,该股指的价格包含在HTML标签的一级, <div class="basic-quote"> → <div class="price-container up"> → <div class="price">。
相似的,如果将鼠标悬停在“S&P 500 Index”并点击名字,会看到它包含在<div class="basic-quote"> 和 <h1 class="name">。
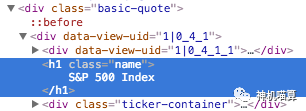
现在我们知道可以通过class 标签辅助定位所需爬取的数据。
代码实践
知道所要爬取的数据位置,那就动起手来开始爬虫。
首先,导入所需的编程库:
# import librariesimport urllib2from bs4 import BeautifulSoup
接着,声明网页URL变量:
# specify the urlquote_page = ‘#/quote/SPX:IND'
然后,使用Python urllib2获取HTML网页:
# query the website and return the html to the variable ‘page’page = urllib2.urlopen(quote_page)
最后,把网页解析成BeautifulSoup格式:
# parse the html using beautiful soap and store in variable `soup`soup = BeautifulSoup(page, ‘html.parser’)
上面soup变量获得网页的HTML内容。我们将从其中抽取数据。
还记得所需爬取数据的唯一层吗?BeautifulSoup能帮我们获取这些层,并使用find()抽取其内容。因为HTML的class标签是唯一的,所以可简单的查询 <div class="name">。
# Take out the <div> of name and get its valuename_box = soup.find(‘h1’, attrs={‘class’: ‘name’})
通过 text函数获取数据:
name = name_box.text.strip() # strip() is used to remove starting and trailingprint name
同样地,我们获取股指价格:
# get the index priceprice_box = soup.find(‘div’, attrs={‘class’:’price’})
price = price_box.textprint price
当运行程序,将会打印S&P 500股指。
导出Excel CSV文件
获取数据之后进行存储,Excel逗号分隔的格式看起来不错。你能用Excel打开查看数据。
首先,导入Python的csv模块和datetime模块:
import csvfrom datetime import datetime
将爬取的数据存储到一个csv文件:
# open a csv file with append, so old data will not be erasedwith open(‘index.csv’, ‘a’) as csv_file:
writer = csv.writer(csv_file)
writer.writerow([name, price, datetime.now()])
执行程序后,你可以打开一个index.csv文件,看到如下内容:
如果每天执行该程序,你无需打开网站即可获得S&P 500股指价格。
进阶使用
这时你可以轻松爬取一个股指,下面举例一次抽取多个股指数据。
首先,更新quote_page变量为一个URL数组:
quote_page = [‘#/quote/SPX:IND', ‘#/quote/CCMP:IND']
然后,将爬取代码加一个for循环,其处理每个URL并将数据存储到data:
# for loopdata = []for pg in quote_page: # query the website and return the html to the variable ‘page’
page = urllib2.urlopen(pg)# parse the html using beautiful soap and store in variable `soup`
soup = BeautifulSoup(page, ‘html.parser’)# Take out the <div> of name and get its value
name_box = soup.find(‘h1’, attrs={‘class’: ‘name’})
name = name_box.text.strip() # strip() is used to remove starting and trailing# get the index price
price_box = soup.find(‘div’, attrs={‘class’:’price’})
price = price_box.text# save the data in tuple
data.append((name, price))
同时,更改存储csv文件部分代码:
# open a csv file with append, so old data will not be erasedwith open(‘index.csv’, ‘a’) as csv_file:
writer = csv.writer(csv_file) # The for loop
for name, price in data:
writer.writerow([name, price, datetime.now()])
现在实现一次爬取两个股指价格。
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



