

Python培训
400-996-5531
400-996-5531
提交Cookie信息模拟微博登录
需要爬取登录之后的信息,大家都是望而止步,不要担心,今天呢,给大家提供一个超级简单的方法,就是提交Cookie信息登录微博,首先,我们找到某明星的微博网址:#/u/1732927460 这里是登录的移动端,你会发现,你点击网址会自动跳转到登录微博的界面(没有跳转的注销掉自己的账号),如下图所示:
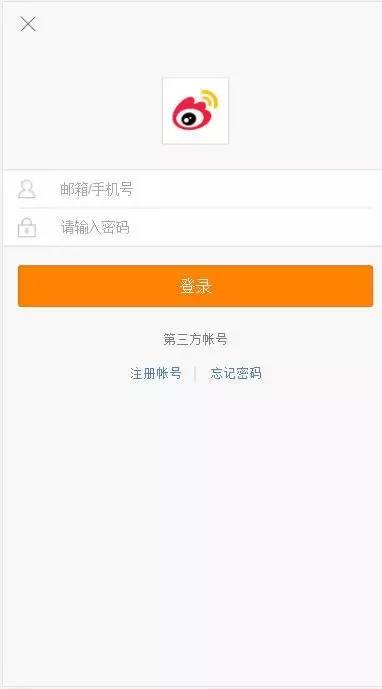
然后登录自己的账号密码,这时记得打开Fiddler进行抓包,如图所示,提取Cookie做为请求某明星微博网址的请求头即可。
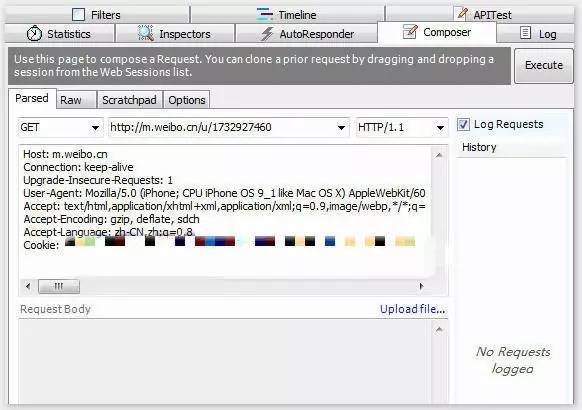
异步加载数据如何爬取
我在网上看过移动端的微博数据很好爬,没有异步加载,可是不知道为什么,我的评论数据就是异步加载的,其实异步加载不可怕,找到相应js包即可,如下图为某明星的一条微博和评论的js包。我们只需请求这个js数据,然后利用json库即可提取我们所需的评论数据。

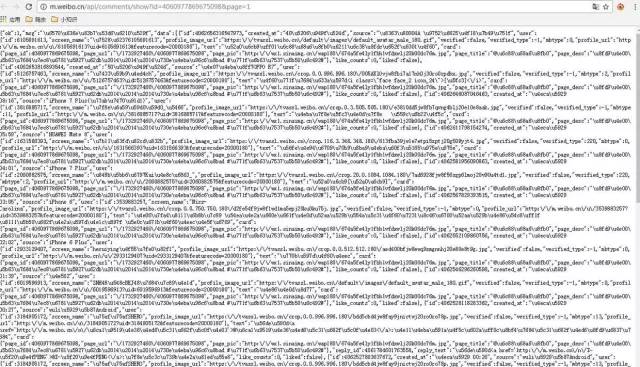
代码
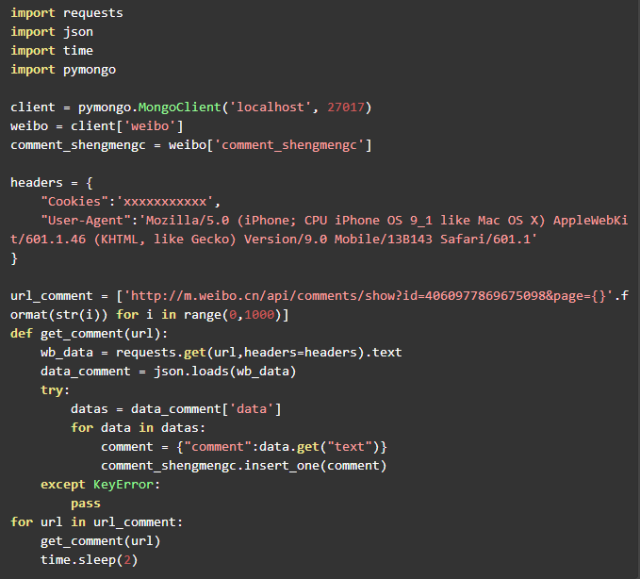
爬取的数据导入数据库后又导出为csv格式进行分析
词云制作及分析

可以说支持的评论更多一些:例如爱你,喜欢,坚强等等;不过也有不少的恶意评论:黑,恶心,讨厌等。
总结
1、Cookie提交是一个简单不错的选择,但Cookie信息隐藏着隐私,大家千万别暴露在外面,以防外人所利用。
2、异步加载不可怕,找包有技巧,有id,vid等字段的嫌疑最大,多练习就行。
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



