

Python培训
400-996-5531
400-996-5531
21世纪以来,在互联网高速发展的背景下,互联网上的信息呈现暴发式的增加,对应的提供人们检索信息功能的搜索引擎也在飞速发展、更新和迭代。
但现有的知名搜索引擎能够触及的互联网内容用九牛一毛来形容也毫不为过。为了给细分领域的客户提供更优质的搜索体验,建立一套自己的搜索引擎就十分重要了。建立一个搜索引擎一般来说需要做这样几件事:
1、利用网络爬虫自动下载网络页面;
2、对爬取结果建立高效快速的索引;
3、根据相关性对网络进行准确的排序。
目前的爬虫技术一般分为两种:通用网络爬虫和主题网络爬虫。
通用网络爬虫一般尽可能多的采集页面,而一般不关心被采集页面的顺序与页面主题的相关性。Google和百度等公司均采用通用网络爬虫。
主题网络爬虫则根据一个已经预定好的主题进行爬取采集,最终对采集结果进行汇总,其爬取页面具有大量相关性。相对通用网络爬虫,主题网络爬虫所消耗的资源和网络带宽更少,所采集的主题相关性更强,页面的利用率更高。
一、遍历算法
1738年,瑞典数学家欧拉( Leornhard Euler)解决了柯尼斯堡问题,由此,图论诞生,欧拉也成为了图论的创始人。图由一些节点与连接这些节点的弧组成。我们可以把互联网看成一张具有指向无数方向的浩瀚无边的图,每一张网页为图的一个节点,每个网页中的超链接为图中的弧。有了超链接,我们可以从任何一个网页出发,用图的遍历算法,自动访问到每一个页面,然后存储所需要的信息。
图的遍历算法可以分为深度优先搜索(Depth-First Search 简称DFS)和广度优先搜索(Breadth–First Search 简称BFS)。
由于深度优先搜索的遍历方式,在很多情况下会导致爬虫在深度上过“深”地遍历或者陷入黑洞,大多数爬虫不采用深度优先搜索,目前主题爬虫比较常见的是广度优先搜索方式。
广度优先搜索遍历URL策略的基本思路是:将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。

图1
如图1,广度优先遍历搜索(BFS)的访问顺序为:A->B->C->D->E->F->H->G->I 深度优先搜索策略从起始网页开始,选择一个URL进入,分析这个网页中的URL,选择其中一个再进入。如此一个链接接着一个链接地抓取下去,一路走到黑,直到处理完一条路线之后再处理下一条路线。如图1,深度优先遍历(DFS)的访问顺序为:A->B C D E->H->I F->G
不管是哪种方式,理论上都可以保证访问到所有的节点。但是工程上基于稳定性等要求一般采用的都是BFS方式。
二、网络爬虫
本文使用Python语言作为主开发语言。在Python中使用urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。
Python可以使用urllib请求页面获取网页HTML信息,实现如下:
from urllib.request import urlopen
html = urlopen(‘http: www.baidu.com’)
得到源代码后即可使用Xpath或者BeautifulSoup4解析HTML元素,提取所需要数据。以上,即完成一个简单的Web数据采集流程。
但是具体的业务工程往往不是一个简单的流程而已,有时候会采集非结构化数据,需要再由工程人员写下载器,进行非结构化数据的提取;有时候结构化数据是异步加载,需要我们模拟加载的JavaScript代码,再对服务器进行一次请求;对于需要代理才能访问的网站,需要再添加代理IP;还有采集的效率等等一系列问题。
三、HTTP请求头的设计
浏览器与服务器交互是基于超文本传输协议(HTTP,HyperText Transfer Protocol),HTTP是互联网上应用最为广泛的一种网络协议。HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
在爬取网站内容时,HTTP协议中请求头的模拟至关重要,请求头不正确将会导致目标站点返回错误的状态码和无效的字符;例如在对某同城租房模块的数据采集中,先是使用chrome浏览器请求租房页面,查找到浏览器请求目标站点的数据包,分析请求头,然后模拟了一个类似的请求头,代码如下:
headers = [
{
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/*,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
}, # 请求头1
{
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/*,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2',
}, # 请求头2
]
header = random.choice(headers) # 随机选取请求头
其中 'Connection': 'keep-alive', 建议保持打开状态。
我们知道HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求—应答客户端和服务器都要新建一个连接,完成之后立即断开连接(HTTP协议为无连接的协议);当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
http1.0协议中默认是关闭的,需要在http头加入"Connection: Keep-Alive",才能启用Keep-Alive;http1.1协议中默认启用Keep-Alive,如果加入"Connection: close ",才关闭。目前大部分浏览器都是用http1.1协议,也就是说默认都会发起Keep-Alive的连接请求了,所以是否能完成一个完整的Keep- Alive连接就看服务器设置情况。
从上面的分析来看,启用Keep-Alive模式肯定更高效,性能更高。因为避免了建立及释放连接的开销。
以上两个HTTP请求头分别来自不同的浏览器,用这种方式请求,在一定概率上,每次请求都会让服务器以为是来自不同的浏览器发出的,使得服务器会返回完整的HTML页面给爬虫端,爬虫端就可以做出相应的解析,若是返回错误页面、存在页面、或者直接返回一串爬虫无法解析的无效信息,那么提取数据从何谈起。使用测试请求头对爬取数据进行请求测试,若连接爬取多个页面均无出现明显错误,即可进入正式爬取阶段。
但是使用模拟请求头的方式对于异步Ajax加载的数据不好直接定位采集,需要对异步Ajax加载的位置进行请求的重新模拟,要先分析异步请求,再模拟加载请求再请求一次服务器,对于爬虫系统来说是很消耗性能的。所以,一般如果采集多种异步数据,可以采用自动化测试工具Selenium模拟浏览器。
Selenium 是什么?一句话,自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试;安装一下 Python 的 Selenium 库,再安装好 PhantomJS,就可以实现 Python+Selenium+PhantomJS 的一整套体系的连接了!PhantomJS 用来渲染解析JavaScirpy,Selenium 用来驱动以及与 Python 的对接,Python 进行后期的处理。
利用Selenium模拟的浏览器能够更加逼真模拟真实Web请求环境,对于Ajax异步加载的数据可以快速定位。
但是在进行模拟爬取时,若触发网站的防爬机制,那么就必须进行多IP的模拟和对爬取线程采取暂时暂停,两者相结合的办法来测试防爬机制的临界点,对于多IP的模拟可以采取二分折半测试的办法,先取一个比较长的暂停时间。然后如果能使程序正常进行就再缩短一倍时间,否则扩大一倍时间,直到有一个临近的值或者区间,再对该临界值或者区间取随机数暂停爬取线程。
具体请求代码如下:
def get_soup (url) :
#('Prepare analytical this URL:')
#(url)
print('准备解析该链接:', url)
# dis = { url : url }
# print(dis)
try:
try:
# 伪装成浏览器
headers = [{
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/*,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
}, {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/*,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2',
}, {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/*,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17',
},
]
header = random.choice(headers)
# 使用代理IP
proxy_ips = [
{'http:': '117.90.3.226:9000'},
{'http:': '210.136.19.75:8080'},
{'http:': '118.186.219.164:8080'},
{'http:': '121.232.147.177:9000'},
{'http:': '117.90.5.48:9000'},
{'http:': '138.186.84.129:8080'},
{'http:': '125.81.105.134:8998'},
{'http:': '114.253.210.125:8118'},
{'http:': '60.160.128.10:9999'},
]
proxy_ip = random.choice(proxy_ips)
proxy_support = urllib.request.ProxyHandler(proxy_ip)
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
# 请求
sleep(0.2)
request = Request(url=url, headers=header)
sleep(0.3)
response = urlopen(request)
except (HTTPError, URLError) as e:
logger.error('URL Error or HTTPError:')
logger.error(e)
print("请求有问题", e)
return None
try:
the_page = response.read()
soup = BeautifulSoup(the_page, "html.parser")
# 判断是否有验证码 (得到所有soup的title)
title_value = soup.title.string.encode('utf-8')
# 验证码页面的title.encode('utf-8')
verification_code = "请输入验证码".encode('utf-8')
# (出现验证码了){阻塞或者暂停6666秒}
if title_value == verification_code:
logger.warning('Boom.........verification_code ow!!!!!!!!!!!!!!!!!!!!!!!!!!!')
logger.warning('sleeping.......')
sleep(2222)
# name = input("The bomb is about to explode,Please input your ame:\n")
# print("Hello,", name)
# logger.warning('The bomb is about to explode')
# logger.warning(name)
soup = get_soup(url)
logger.warning('(warning)Revisit the link:')
logger.warning(url)
return soup
except AttributeError as e:
logger.error('AttributeError(Request soup)')
logger.error(e)
return None
return soup
except Exception as e:
logger.error('another Exception(Request soup)')
logger.error(e)
return None
四、HTML网页的解析
爬虫请求成功后,返回Soup,即HTML的源代码。
HTML页面中包含着大量的文本、链接、图片等信息,所有的HTML都以,<HTML>开始</HTML>结束。所有的HTML源代码中均包含着大量的如<title></title>、<from>等标签,众多标签构成了完整的HTML文档。DOM全称 Document Object Model,即文档对象模型。将文档抽象成一个树型结构,文档中的标签、标签属性或标签内容可以表示为树上的结点。
HTML文档转换为HTML DOM节点树如图2所示:
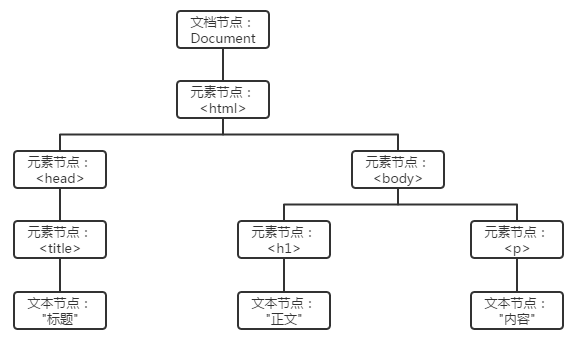
图2
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc)
print(soup.prettify())
<html>
<head>
<title> ansc story </title>
</head>
<body>
<p> <b> ansc story </b> </p>
</body>
</html>
几个简单的浏览结构化数据的方法:
☛Soup.title 输出内容:<title> ansc story </title>
☛soup.title.name输出内容: u'title'
☛soup.title.string输出内容:u' ansc story '
将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄。
在Beautiful Soup中最常用的函数为find_all()和find()。
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件
find_all( name , attrs , recursive , text , **kwargs )
name 参数
name参数可以查找所有名字为name的tag,字符串对象会被自动忽略掉。搜索 name参数的值可以是任一类型的过滤器。
keyword 参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为id的参数,Beautiful Soup会搜索每个tag的“id”属性。
按CSS搜索
按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字 class 在Python中是保留字,使用class做参数会导致语法错误。从Beautiful Soup的4.1.1版本开始,可以通过 class_ 参数搜索有指定CSS类名的tag。
text 参数
通过text参数可以搜素文档中的字符串内容,与 name 参数的可选值一样,text 参数接受字符串、正则表达式、列表、True。
limit 参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢。如果我们不需要全部结果,可以使用limit参数限制返回结果的数量。效果与SQL中的limit关键字类似,当搜索到的结果数量达到limit的限制时,就停止搜索返回结果。
find(name,attrs,recursive,text,**kwargs)
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果。比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适,使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法。
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是一个Python对象,所有对象都可以归为4个种类:Tag ,NavigableString ,BeautifulSoup , Comment 。所以在解析HTML时,即是在操作Beautiful Soup里头的一个个Python对象。Beautiful Soup提供了强大的函数库,所以任何HTML(或XML)文件的任意节点信息,都可以被提取出来,只要目标信息的旁边或附近有标记即可。
数据经过清洗过滤之后提取出来,写入文本文件或者持久化到MySQL。对于已经持久化到MySQL的数据,一方面可以进一步对该主题数据进行数据挖掘,另一方面可以利用Java强大的Web处理能力展示数据,利用纯Javascript图表库ECharts, 进行数据的可视化展示。
本文内容转载自网络,本着分享与传播的原则,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



