

Python培训
400-996-5531
400-996-5531
为快速了解是否有用,直接先给出最终能得到的效果:
(如果没有,看它作甚)
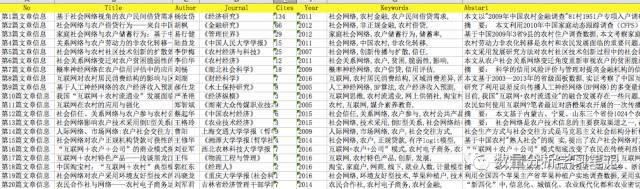
这是我们得到的文献信息文件。

说明:
每次查询程序自动生成两个文件,一个是xlsx格式文件(方便整理信息),一个是txt文件,方便查看文献。
txt文件内容:

xlsx文件内容:
2. 文件名称是自动的生成的
既然偷懒自然要偷懒到底,所以,程序会根据你设定的查询文献篇数,中文还是英文,查询多少篇等等信心 自动生成对应的文件名称。
3. 能够查询什么内容呢。

这个和“高级搜索”的方式差不多,只是这里使用修改参数,可以一次查询任意篇文献信息并保存下来。 当然可以自定义查中文文献还是英文文献。
(说明:如果关键词是 两个以上中文词 的时候,查英文文献是查不到的,这个是学术百度自己的规则,这个“锅”不该本程序背)
另外,除了主题、起始页和终止页 必须填写外,其他参数,可以是空值。
(每页对应10篇文章信息)
4. 查询失败情况。
在不同查询的时候回存在少量的查询失败的情况,这个“锅”该扔给谁呢,扔给百度一半吧, 这主要是因为,百度学术呈现的信息来源较多,信息呈现的规范性不足,这也是比较百度学术比较大的一个“坑”。
例如:爬取 文章发表的文献名称时,有时候定义在“sc_journal”里面,但有时候又定义在"sc_conference"里面。
还有很多种情况,我发现的问题,我都兼容过了,不过还是存在一些其他参数放置位置不一致的情况,如果去查找所有的不一致规则,去修改程序兼容,工作量太大,所以,没有精力去完善,不过这样的情况相对较少,所以,谁有兴趣完善一下,那就太感谢了。
为了弥补这种情况,我专门设定了如果查询某一篇文献失败,就会显示文献信息对应的URL:
复制这个URL,到浏览器中打开:
双击-->检查(或 审查元素)-->Network-->刷新页面-->doc-->Preview
就可以得到如下界面:

查询失败文章的信息 就都在这个meta-di-info里面,可以点开补充。
(实际上,查询100篇信息,大概也就几篇文章会出现规则不一致,所以,问题不算严重,不是太严格的话,忽略不计也没有问题)
想想,其他应该也没什么了。
-------------------------------------------
利用Python3.6写了如何爬取CNKI上的主题文献信息,后来想想,似乎CNKI上的文献资源相对局限,百度学术上的文献资源更加丰富,因此,扩展了代码,用于百度学术资源的快速获取。
百度学术上能获取英文文献资源,是一个较大的优势,并且资料来源较为丰富。

--------------------------------------
完整代码如下(如果有人基于此程序程序扩展或完善,欢迎交流):
------------------------------------
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 18 22:10:28 2017
@author: Liu Kuanbin
"""
#----------------------------------加载将会使用到的函数库
import requests # 读取网页
from lxml import etree # 用于解析网页
from openpyxl import Workbook # 创建表格并用于数据写入
import urllib
#------------------定义获取文章列表对应的链接的函数
def get_data(urllist,headers,i):
j=0 # 初始化j的取值
for urli in urllist:
try:
j=j+1
num=10*(i-pagestart)+j # 第多少篇
test='http://xueshu.baidu.com'+str(urli) # 单篇文章对应的页面网址
code=requests.get(test)
file=code.text.encode(code.encoding).decode('utf-8') # 对网页信息进行转化成为可以正常现实的 UTF-8格式
r=etree.HTML(file) # 获取网页信息,并且解析 使用xpath
#--- 因为存在不同的数据来源,有些来源无法获取数据,因此循环获取来源,直到可以获取
for k in range(0,8):
p1=r.xpath('//div[@class="allversion_content"]/span/a/@data-url')[k] # 选择不同的来源链接
p2=r.xpath('//div[@class="abstract_wr"]/p[2]/@data-sign')[0]
url_alli='http://xueshu.baidu.com/usercenter/data/schinfo?url='+p1+'&sign='+p2
if len(urllib.request.urlopen(url_alli).read())>100:
break
#---------------------------------------------------------------------
file=requests.get(url_alli).json()
ws.cell(row=num+1,column=1).value='第'+str(num)+'篇文章信息'
ws.cell(row=num+1,column=2).value=file["meta_di_info"]["sc_title"][0] # 获取 文章标题
ws.cell(row=num+1,column=3).value=file["meta_di_info"]["sc_author"][0]["sc_name"][0] # 获取第一作者
ws.cell(row=num+1,column=5).value=file["meta_di_info"]["sc_cited"][0] # 引用次数
ws.cell(row=num+1,column=6).value=file["meta_di_info"]["sc_year"][0] # 发表刊物时间
ws.cell(row=num+1,column=8).value=file["meta_di_info"]["sc_abstract"][0] # 获取 文章摘要
# 容易出问题的地方
# 1. 获取发表刊物
try:
journal=file["meta_di_info"]["sc_publish"][0]["sc_journal"][0] # 期刊
except:
journal=file["meta_di_info"]["sc_publish"][0]["sc_conference"][0]
ws.cell(row=num+1,column=4).value=str(journal)
# 3. 关键词
try:
keyw=file["meta_di_info"]["sc_keyword"]
key=''
for item in range(len(keyw)):
key=key+keyw[item]+','
except:
key=''
ws.cell(row=num+1,column=7).value=key # 关键词
# print('爬虫'+str(10*(pageend-pagestart+1))+'篇文章信息的第'+str(num)+'篇爬取成功!!')
print('爬虫第'+str(i)+'页中的第'+str(j)+'篇爬虫成功!!')
with open('百度学术关于'+'”'+liu_key+'"''前'+str(10*(pageend-pagestart+1))+'篇'+lang+'文献'+'按照'+paixu+'排序.txt','a',encoding='utf-8') as f: # 新建一个pinglun的txt文件,用二进制方式,编码方式 UTF-8 ,句柄名为f
f.write(file["meta_di_info"]["sc_title"][0]) # 文章题目
f.write('\n')
f.write(file["meta_di_info"]["sc_author"][0]["sc_name"][0]) # 作者
f.write('-')
f.write(file["meta_di_info"]["sc_year"][0]) # 年份
f.write('-')
f.write(file["meta_di_info"]["sc_cited"][0]) # 引用量
f.write('-')
f.write(str(journal)) # 文章发表刊物
f.write('\n')
f.write(file["meta_di_info"]["sc_abstract"][0]) # 获得文章摘要
f.write('\n\n')
except:
print('爬虫第'+str(i)+'页中的第'+str(j)+'篇爬虫失败')
print(url_alli)
#---创建表格,待接收数据信息---#---------------------------------------------------
wb = Workbook() # 在内存中创建一个workbook对象,而且会至少创建一个 worksheet
ws = wb.active #获取当前活跃的worksheet,默认就是第一个worksheet
ws.cell(row=1, column=1).value ="No"
ws.cell(row=1, column=2).value ="Title"
ws.cell(row=1, column=3).value ="Author"
ws.cell(row=1, column=4).value ="Journal"
ws.cell(row=1, column=5).value ="Cites"
ws.cell(row=1, column=6).value ="Year"
ws.cell(row=1, column=7).value ="Keywords"
ws.cell(row=1, column=8).value ="Abstart"
#-----------------------------------------------------------------------------参数设置区
wd='互联网' # 主题控制:此行设置搜索主题
english=0 # 关键词是 中文=0 英文=1
pagestart=1 # 起始页
pageend=2 # 终止页
sort='' # 排序控制:sc_cited=引用量 sc_time=时间 默认为相关性排序 (空值的时候 就是相关性排序查询了)
sc_tr=6 # 希望搜索文章语言类型: 1=中文 6= 英文
style='' # 类型: 1=期刊 ;2=学位论文; 3=会议论文; 4=图书; 5=专利;
autor='' # 作者姓名控制
#-----------------------------------------------------------------------------文件名称定义
liu_key=wd
if len(sort)>2:
paixu=sort
else:
paixu='相关性'
if sc_tr==1:
lang='中文'
elif sc_tr==6:
lang='英文'
#-----------------------------------------------------------------------------参数设置区
#-----排序处理
if len(sort)==0:
sort=''
else:
sort='&sort='+sort
#-----语言处理
if len(str(sc_tr))==0:
sc_tr=''
else:
sc_tr='&sc_tr='+str(sc_tr)
#-----文章筛选处理处理
if len(style)==0:
style=''
else:
style='&filter=sc_type={'+style+'}'
#-----文章类型筛选处理
if len(autor)==0:
autor=''
else:
autor='&tag_filter= authors:('+autor+')'
# 生成 URL
if english==0:
url='http://xueshu.baidu.com/s?wd='+wd+'&ie=utf-8'+sort+sc_tr+style+autor
elif english==1:
url='http://xueshu.baidu.com/s?wd='+wd+'&ie=utf-8'+sort+style+autor
#-----------------------------------------------------------------------------参数设置区
urlip = '#/nt/' # 提供代理IP的网站
headers={
'Referer':'http://hm.baidu.com/hm.js?43115ae30293b511088d3cbe41ec09',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Cookie':'BAIDUID=D0CB679BEEF23F82EEDAF6DF18F4FEFF:FG=1; PSTM=1510625999; BIDUPSID=06E79C7EE33716F5BE38D223303FD8B2; HMACCOUNT=AF4DA2CBBA0B0EEC; pgv_pvi=8289640448; pgv_si=s5000054784; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDRCVFR[w2jhEs_Zudc]=mk3SLVN4HKm; PSINO=2; H_PS_PSSID=',
}
headers2={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
#------------------------------------------------------------------------------数据收集和处理
for i in range(pagestart,pageend+1):
# print('获得每一页里面文章的 urllist')
url_all=url+'&pn='+str(10*(i-1))
print(url_all)
#----------------------获得每一页的文章具体文章信息页面的链接
response=requests.get(url_all,headers=headers) # 获得网页源码 ,proxies=proxies
# print(utf16_response.decode('utf-16'))
file=response.text.encode(response.encoding).decode('utf-8') # 对网页信息进行转化成为可以正常现实的 UTF-8格式
r=etree.HTML(file) # 获取网页信息,并且解析 使用xpath
urllist=r.xpath('//div[@class="sc_content"]/h3/a[1]/@href') # 获得当前页所有文章的进入链接
# 获得每页urllist的文章信息,并且存到构建的表格中
get_data(urllist,headers,i)
wb.save('百度学术关于'+'”'+liu_key+'"'+'前'+str(10*(pageend-pagestart+1))+'篇'+lang+'文献'+'按照'+paixu+'排序.xlsx') # 最后保存搜集到的数据
本文内容转载自网络,本着分享与传播的原则,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



