

Python培训
400-996-5531
400-996-5531
本文适用场景:需要频繁从固定网站抓取表格数据,并进行简单的数据可视化操作。在这篇案例中,简约而不简单地插入了MySQL与python、pandas的互动操作,供后续在更广泛的场景中参考。
Python基于2.7版本,MySQL Community Server 版本为5.7.16
本次案例的主要步骤如下:
编写爬虫,爬取#上全国主要城市的实时环境监测信息。
调用MySQLdb接口,把数据存储进数据库
调用MySQLdb接口,基于分析目的,查询目标数据,进行分析(此处为可视化分析)
有了爬虫小工具,可以很轻松地应付重复性的体力劳动和排版工作了。本文的代码如下:
import pandas as pdimport numpy as npimport requestsfrom bs4 import BeautifulSoupimport refrom datetime import datetimeimport MySQLdb as mdbimport seaborn as snsimport matplotlib.pyplot as pltfrom matplotlib.font_manager import FontPropertiesdef download_info(url): ret = requests.session().get(url) #通过request读取url soup = BeautifulSoup(ret.text,'lxml') #用bs4进行解析 rank_content = soup.find(class_="pj_area_data_details rrank_box") #用class属性进行定位 nodes = rank_content.find_all('li') info = [] for node in nodes: rank = ode.find(class_='pjadt_ranknum').text.strip() level = ode.find(class_=re.compile('^pjadt_quality_bglevel')).text.strip() city = ode.find(class_='pjadt_location').text.strip() link = ode.a.attrs.get('href').strip() province = ode.find(class_='pjadt_sheng').text.strip() AQI = ode.find(class_='pjadt_aqi').text.strip() [pm25, unit]= ode.find(class_='pjadt_pm25').text.strip().split(' ') time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') info.append([rank,level,city,link,province,AQI,pm25,unit,time]) return infodef write_db(info): connect = mdb.connect(db='test',host='localhost',user='root',passwd='123',charset='utf8') #创建连接 cur = connect.cursor() #创建游标,所有的MySQL的操作都是基于游标来执行的 sql = '''create table if not exists air_quality_record (id int not null auto_increment, rank int not ull, level varchar(20), city varchar(20), link varchar(40), province varchar(20), aqi int, pm25 int, unit varchar(20), time datetime, primary key (id))''' cur.execute(sql) sql = '''insert into air_quality_record (rank,level,city,link,province,aqi,pm25,unit,time) values (%s,%s,%s,%s,%s,%s,,%s,%s,%s)''' cur.executemany(sql,info) connect.commit() #需要使用该命令,以确保sql修改语句生效 cur.execute('select province, api from air_quality_record where id>=1 and id<=361') data = cur.fetchall() #获取sql语句的查询内容 cur.close() #关闭游标 connect.close() #断开连接 df = pd.DataFrame(np.array(data),columns=[ 'Province', 'AQI']) df['AQI'] = df['AQI'].astype(#16) return dfdef figure_plot(df,kind): myfont = FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf') with sns.color_palette(): sns.set(font=myfont.get_name()) sns.factorplot(x='Province',y='AQI',data=df,kind=kind,size=6,aspect=2) plt.title('Air Quality Index of Each Province') plt.show()if __name__ == '__main__': url = '#/rank.html' df = write_db(download_info(url)) for kind in ['box','swarm']: figure_plot(df, kind)
演示效果如下:

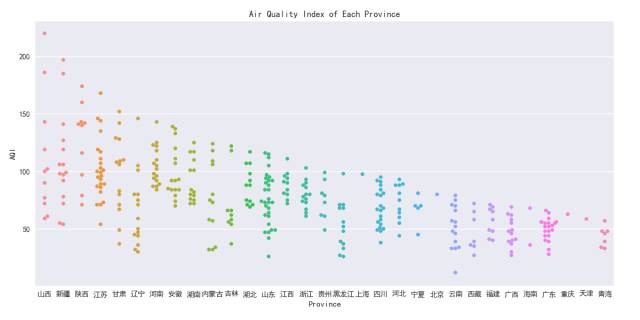
主要第三方库简介:
requests,BeautifulSoup
是基于urllib封装的第三方python库,使用起来非常简单。BeautifulSoup是python的一个库,最主要的功能是从网页抓取数据。常见的get url的操作、用lxml对获取的html文档进行解析,以及常用的解析方法(find_all,attrs.get)均在案例中有涉及。
MySQLdb
MySQLdb 是用于Python链接Mysql数据库的接口,它实现了 Python 数据库 API 规范 V2.0,基于 MySQL C API 上建立的。可以从:#/pypi/MySQL-python 进行获取和安装,而且很多发行版的linux源里都有该模块,可以直接通过源安装。
本文内容转载自网络,本着分享与传播的原则,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



