

Python培训
400-996-5531
400-996-5531
走了很多弯路,看了很多风景,才发现,想要好好学算法,还是要一行一行敲代码,于是有了这个系列。
这个系列按照机器学习实战的章节来写,由于市面上已经有很多同类的文章,一般以介绍算法,贴代码,举例子为主,个人读下来,觉得对于实现的代码还是不能有很好的理解,所有有了这个系列。要写这个系列还有三个原因:
实战的代码是Python2的,有一些用法已经在python3中不支持了,以后的系列都以pyhton3完成,遇到python2不支持的坑,会进行一下对比
有一些初级的函数在初学阶段是需要积累的,孤立的去记忆比较费时费力,所以一边学算法的实现,一边把遇到的一些函数的用法记录下来~
遇到有趣的pythonic的表达,记录分享出来,做知识积累。
knn介绍
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。平常生活中我们都会下意识的运用到我们的判断中,比如富人区和穷人区,判断一个人是富人还是穷人根据他的朋友的判断,就是运用了kNN的思想。
KNN是通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离:
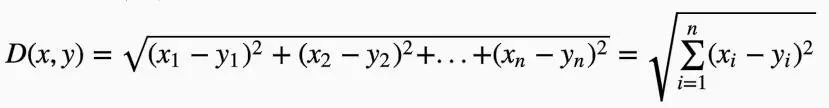
或曼哈顿距离
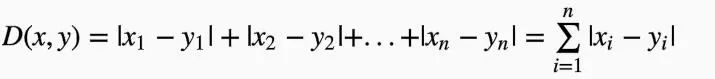
欧式距离和曼哈顿距离都是闵可夫斯基距离(Minkowski Distance)$p=2$和$p=1$的特例,定义为:
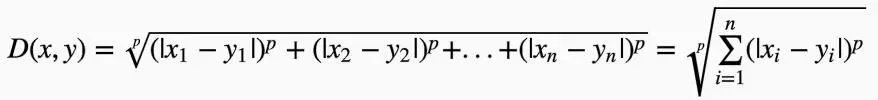
KNN算法实现
本节主要参考刘建平Pinard的博文K近邻法(KNN)原理小结,刘建平Pinard的博文对每个算法有很深刻的见解,一般在看不懂李航的《统计学习方法》的时候,去看刘大大的博客会有豁然开朗的感觉。他博文中提到scikit-learn里只使用了蛮力实现(brute-force),KD树实现(KDTree)和球树(BallTree)实现,所以他的这篇文章中只讨论这几种算法的实现原理。其余的实现方法比如BBF树,MVP树等没有做讨论,需要对算法有更深一步了解的童鞋,移步刘建平Pinard的文章~
实战代码
这一部分主要是参考实战,然后主要讲解一些具体的实现~
下面的代码为运行程序导入所需要的库
from numpy import *import operator
下面的程序主要实现了生成测试数据的功能
def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group,labelsgroup,labels = createDataSet()
输出:
In [2]:groupOut[2]: array([[ 1. , 1.1], [ 1. , 1. ], [ 0. , 0. ], [ 0. , 0.1]])
In [3]: labelsOut[3]: ['A', 'A', 'B', 'B']
下面的代码主要实现了利用knn分类的功能
def classify0(inX,dataSet,labels,k): dataSetSize = dataSet.shape[0] #tile 扩展矩阵的函数 diffMat = tile(inX,(dataSetSize,1))-dataSet sqdiffMat = diffMat**2 sqDistances = sqdiffMat.sum(axis = 1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() print(sortedDistIndicies) classCount={} for i in range(k): voteLabels = labels[sortedDistIndicies[i]] #dict.get 获取指定键的值,默认返回none,键值不存在时,不同于dict['key']直接返回error,也可以指定,下面指定为0 classCount[voteLabels] = classCount.get(voteLabels,0)+1 print(classCount) #Python3.5中:iteritems变为items(python2 classCount.iteritems()) #items可以输出dict中的(key,value) #sorted中的key参数传入函数,operator.itemgetterr函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值。 #operator.itemgetter(1) 为获取classCount.items()中的第二个参数 sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse = True) print(sortedClassCount) return sortedClassCount[0][0]
给定输出,给出分类值
In [7]: classify0([0,0.2],group,labels,2)[3 2 1 0]{'B': 2}[('B', 2)]Out[6]: 'B'
深度解读实战代码
argsort函数
argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。
输出是按照从小到大的顺序输出的
例子:
import numpy as npa = np.array([2,0,4,1,2,4,5])a.argsort()
输出为a从小到大排序后的index:
Out[12]: array([1, 3, 0, 4, 2, 5, 6], dtype=int64)
输出为list的index,提取出来就是list从小到大的排序
dict.get vs dict[‘key’]
a = {'name': 'wang'}
dict[‘key’]输出
a['age']Out[16]: KeyError: 'age'
dict.get输出:
a.get('age')a.get('age', 10)Out[17]: 10
dict[‘key’]只能获取存在的值,如果不存在则触发KeyError
而dict.get(key, default=None)则如果不存在则返回一个默认值,如果设置了则是设置的,否则就是None
Python中sort 和 sorted函数
用sort函数对列表排序时会影响列表本身,而sorted不会
a = [1,2,1,4,3,5]a.sort()aOut[18]: [1, 1, 2, 3, 4, 5]
sort函数改变了a的顺序
a = [1,2,1,4,3,5]sorted(a)aOut[19]: [1, 2, 1, 4, 3, 5]
sorted未改变a的顺序
sorted函数
sorted(iterable,cmp,key,reverse)(pyhton2的用法)
python3 sorted取消了对cmp的支持。
list1 = [('david', 90), ('mary',90), ('sara',80),('lily',95)]sorted(list1,cmp = lambda x,y: cmp(x[0],y[0]))TypeError: 'cmp' is an invalid keyword argument for this function
用key函数排序
sorted(list1,key = lambda list1: list1[0])Out[23]: [('david', 90), ('lily', 95), ('mary', 90), ('sara', 80)]
list1[0]表示用list中的第一个元素排序
sorted(list1,key = lambda list1: list1[1])Out[24]: [('sara', 80), ('david', 90), ('mary', 90), ('lily', 95)]
list1[1]表示用list中的第二个元素排序
三道sorted面试题
1)key函数的运用
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave','B', 10)]sorted(students,key=lambda s: s[2]) #按照年龄来排序
2)多个字符的排序
‘asdf234GDSdsf23’这是一个字符串排序,排序规则:小写<大写<奇数<偶数
s = 'asdf234GDSdsf23' #排序:小写-大写-奇数-偶数#解法1:print("".join(sorted(s, key=lambda x: (x.isdigit(),x.isdigit() and int(x) % 2 == 0,x.isupper(),x))))Out[25]: addffssDGS33224#解法2:print("".join(sorted(s, key=lambda x: (x.isdigit(),x.isupper(),x.isdigit() and int(x) % 2 == 0,x))))Out[26]: addffssDGS33224
解释:
Boolean 的排序会将 False 排在前,True排在后 .
1.x.isdigit()的作用是把数字放在后边,字母放在前边.
2.x.isdigit() and int(x) % 2 == 0的作用是保证奇数在前,偶数在后。
3.x.isupper()的作用是在前面基础上,保证字母小写在前大写在后.
4.最后的x表示在前面基础上,对所有类别数字或字母排序。
若不进行第四步,每个内部是未排序的,但是整体顺序是按照要求排序的
print("".join(sorted(s, key=lambda x: (x.isdigit(),x.isupper(),x.isdigit() and int(x) % 2 == 0))))Out[27]: asdfdsfGDS33242
3) 特殊需求的排序
list1=[7, -8, 5, 4, 0, -2, -5]
要求1.正数在前负数在后 2.整数从小到大 3.负数从大到小
#解法1:sorted(list1,key = lambda x:(x<0,x<0 and -x,x))Out[28]: [0, 4, 5, 7, -2, -5, -8]解法2:sorted(list1,key=lambda x:(x<0,abs(x)))Out[29]: [0, 4, 5, 7, -2, -5, -8]
讲完这几个函数,对照机器学习实战的源代码,理解和实现kNN算法就是手到擒来了~小编也是第一次尝试这样的写作风格,有任何意见和想法请及时和小编联系,小编会继续努力哒~
参考资料
K近邻法(KNN)原理小结
Python中sort 和 sorted函数
李航. 统计学习方法[M]. 清华大学出版社, 2012.
周志华. 机器学习 : = Machine learning[M]. 清华大学出版社, 2016.
哈林顿李锐. 机器学习实战 : Machine learning in action[M]. 人民邮电出版社, 2013.
本文内容转载自网络,来源/作者信息已在文章顶部表明,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



