

Python培训
400-996-5531
400-996-5531
这篇文章适合任何会简单英语和基础电脑操作的任何人。这篇笔记从安装Python开始,用最通俗的语言向大家分享我的Python机器学习记录,主旨在帮助大家对如何用Python做Project有个基本的印象,所以大家再读的时候以理解分析思路为主,不需要太过纠结具体的代码。个人建议先无脑复制黏贴一遍,之后再细细思考,需要的话,可以google查询我没有覆盖到的具体用法。
看到文章的大神可以私信我改进的方向,公共区域给我留点面子,谢谢。
我第一次学习Python3时,把基础教程过了一边。呵呵呵,看完第二页,第一页的知识点已经忘了。 So happy. 后来才意识到直接上手,哪里不会查哪里才是正确的打开方式。
这个机器学习的案例和数据来自机器学习竞赛网站Kaggle的入门案例,大家做完了之后可以看到自己在9000+参赛者的排名
Titanic: Machine Learning from Disaster
#/c/titanic
目的是根据泰坦尼克号乘客的基本信息来推测其生还机率。在这里大家可以顺便把这次用的数据下载好。
获取数据
登陆Kaggle, 没有的话注册一个先。
在这个页面获取Titanic的数据
#/c/titanic/data
同时下载test.csv, 和 train.csv.
train.csv文件里包含一部分乘客的信息,和他们是否生还的结果。
test.csv文件里只有乘客信息,没有结果。
我们要观察train.csv里什么样的乘客更容易生还,或死亡。
来根据test.csv的乘客信息,推测他们的生还结果。
这种文件格式可以用excel打开,大家可以打开观察一下。因为这个文件比较小,太大的文件就打不开了。
CSV也可以用笔记本打开,就会发现它里面所有的数据都是用逗号分隔的,大家知道就好。之后会用到。
安装Python3 和PyCharm
首先下载python3
#/downloads/release/python-364/
在上面链接的最后部分选择适合自己系统的安装器(installer)。
接着向大家严重安利对新手超级友好的PyCharm, 清爽干净上档次,还免费。同时也避免了很多新手容易遇到的类似环境设置问题。反正下载这个就对了。超级省心!
PyCharm = Python的衣服(我们叫shell)
下载时,请选择免费的Community版本。呵呵呵,贫穷如我。
#/pycharm/download
在下面的setup步骤中,32位或者64位大家可以自己按照电脑选择下
下面的.py是关联Python的文件格式,大家可以打勾。
最底下的Jetbrain,我选择先不下载。
安装中,UI theme的选择我比较喜欢Darcula, 感觉比较炫酷,并且,嗯...不会读。
安装好了以后,打开PyCharm, 新建一个project, 我给它起名叫titanic。
接着会出现tips窗口,直接关掉就好啦(我上次看了二十分钟还没看完,放弃了...)
现在界面是这个样子
干净清爽大气高端上档次,我好喜欢!!!!
问题来了,说了半天,到底什么是Python?
我感觉Python是让电脑干活的的一种语言。很乖很听话,你让他倒水他就倒水,让他做饭他就做饭,唯命是从,这就是Python.
以我浅薄的理解,用户和Python有两种姿势的play(交流), 嘿嘿嘿。
第一种交流方式,点击Pycharm左上角File, 然后new scratch file. 然后在语言里选择Python.
这是写程序的交流, 你可以通过写程序告诉python, 他先干嘛再干嘛,然后点击运行,达成你想要的结果。
举个例子,假如有个女朋友,你写个行动手册告诉她。“Baby,你去桌子上拿一个水杯,然后去饮水机, 接水,走回来,温柔的说‘啊’, 然后喂我喝水。” 好了点击运行(Run)手册。 你就可以喝到水了。
这张方式叫做模块(Module),会形成一个 Python 文件,以.py结尾
第二种交流方式,点击Pycharm左上角Tools, 选择Python Console.
这是一种互动的交流。
举个例子,假如有个女朋友:
我: “Baby, 你去桌子上拿个水杯。”
“女朋友”:“拿到了”
我: “去饮水机接水”
“女朋友”:“接好了”
我: “走回来”
。。。。。。。
大概这个流程,一个步骤,一个动作,一个步骤,再一个动作的走。
这次我们会用到第二种, 大家现在可以把scratch_1.py 关掉了, 把空间留给Python Console就好。现在长这样。
整个项目的脉络大概是这样的:
观察数据(买菜),主要通过画图,来了解乘客基本信息,和他们生还率的关系
清理数据(切菜), 把文字数据转换成计算机可以分析的数字。(同时去掉不相关的数据)
建立机器学习模型(炒菜), 让机器分析数据, 寻找变量间的关系,最后做预测
安装我们这次要用的“包”(是别人写好的模块)
不是这个包!!!!

Python的包可以理解为帮助我们达成目标的小工具。
举个例子,
上图就是一种为达到目的,很实用的小工具。
为了安装包,打开pycharm左下角的小按钮,选择Terminal (Python Console不见了没关系,可以随时用老办法打开)。
我们这次要用的小工具有
pandas: 数据处理小能手
numpy: 数据处理小能手2
matplotlib: 画画小能手
seaborn: 画画小能手2
sklearn: 机器学习小能手
接下来依次输入以下代码到Terminal(只可以手打,每打完一行要按回车,安装完一个再安装下一个)
pip install pandas
pip install numpy
pip install matplotlib
pip install seaborn
pip install sklearn
pip 是用来安装其他包的小工具。
安装好了以后就可以退出Terminal了,再次打开Python Console.
包安装好了以后,要先在Python Console中加载才可以使用,可以在Python Console先加载 pandas, matplotlib 和 umpy三个包,Python不见了的话可以用前面的方法调出来:
在编程的时候,想换行的话可以按住shift再按enter
import pandas as pdpd.options.display.max_columns = 100from matplotlib import pyplot as pltimport matplotlibmatplotlib.style.use('ggplot')import numpy as np
import 是加载包的命令, 后面跟包的名字, as后面是你给包设定的比较方便打字的昵称。
第二行是对使用包的设定。
大家可以复制粘贴,然后回车,这里不会有任何反应,光标会重新出现。
加载和可视化分析数据
在Python Console输入以下代码。
这行代码大概可以理解成:设定新变量data, 并且让data等于train.csv里面的数据。
注意这里我们用到了包pandas的昵称(pd),并且使用了它其中的一项的功能read_csv.
括号里要改文件地址,因为现在的地址文件在我电脑上的位置,大家应该是不一样的。值得注意的WINDOWS地址里的斜杠和Python是反的。大家观察下。
相信大家的都能找到写出来,注意地址两端保留单引号。
之后data就代表了train.csv里的所有数据,数据类型是数据框(dataframe)其实很像excel。
data = pd.read_csv('C:/Users/Razer/Downloads/train.csv')
之后我们再敲一行代码看看都有哪些数据。
data.shape
返回(891, 12), 意思是有891行和12个列。
再使用data.head查看前五列,顺便一提数据框里的NaN代表缺失值
data.head()
返回
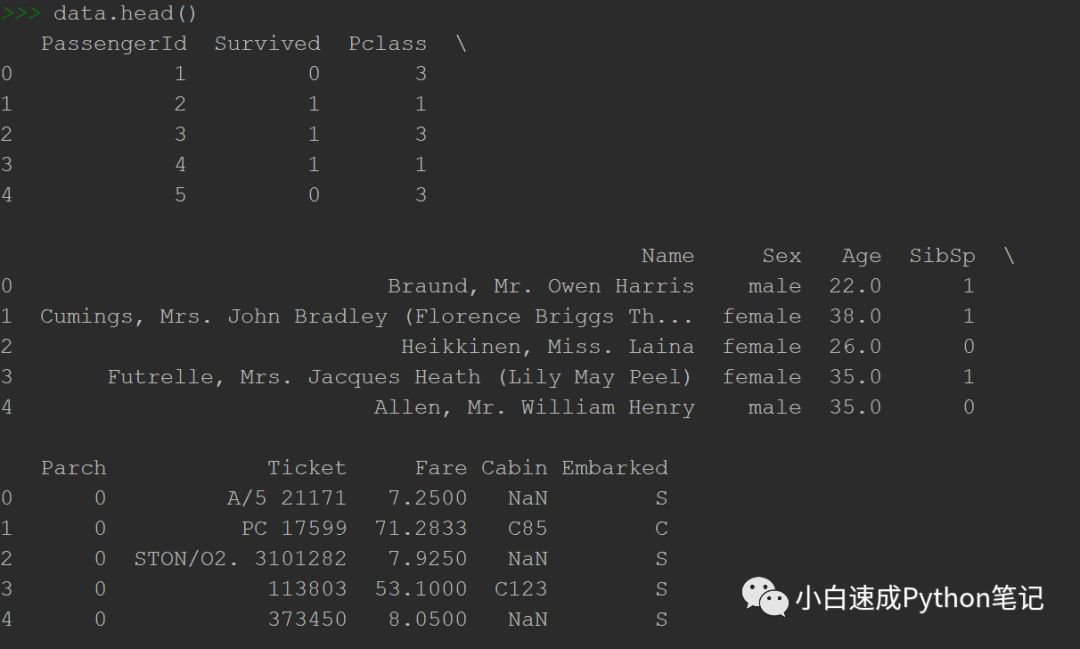
之后用describe查看数据的数值特征
data.describe()
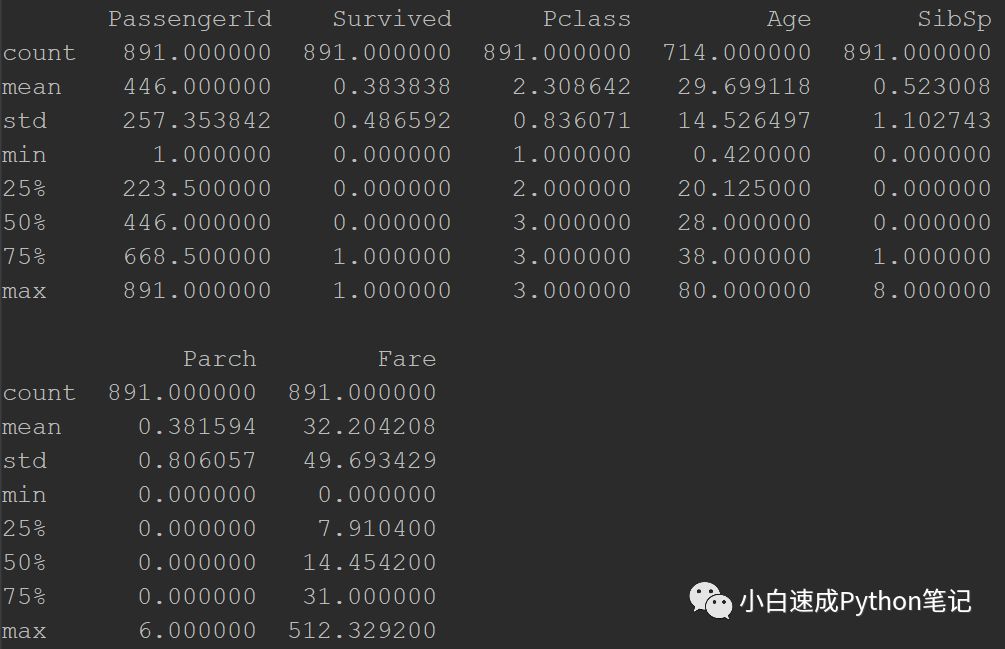
大家可以看到有八个信息, 分别是数量,平均值,中位数,最小值,第一四分位数,中位数, 第三四分位数,最大值。
举例,看到Survived的平均值,大家就知道大概有38%的人生还。
看Age, 就知道大部分都是年轻人和中年人来船上浪,最老的人80岁。
重要的是,Age好像只有714个值,少了177个值。
这里为了接下来画图,我们简单的用代码把这些值换成Age的中位数。
用的是fillna功能,也是pandas的函数。用来替换缺失值。
data['Age']的意思是在data这个数据框里,选出名字是Age的这个列来作为操作对象(Python中所有的文本都要加引号像这里的'Age')
然后使用fillna, 之后在小括号里设置了使用data中的Age的中位数替换缺失值。
更多的使用方法大家可以搜一搜fillna,很容易查到, 之后又没见过的函数,想的话都可以搜搜。
data['Age'].fillna(data['Age'].median(), inplace=True)
运行之后就替换成功。大家可以再用一遍data.describe, 就会看到age被填满了。
接下来就是我们的推测过程了,大家都知道,在titanic这个电影中,逃生的时候是女士优先的,所以我们大胆猜测,女士幸存率更大一些。
这里我们用pandas的功能来画图,
survived_sex = data[data['Survived']==1]['Sex'].value_counts()dead_sex = data[data['Survived']==0]['Sex'].value_counts()df = pd.DataFrame([survived_sex,dead_sex])df.index = ['Survived','Dead']df.plot(kind='bar',stacked=True, figsize=(15,8))
通过上面的代码,我们创建了一个新的数据框survived_sex。
等号右边 data[data['Survived']==1] 代表选出data数据框里所有的幸存者数据['Survived']==1;接着['Sex'].value_counts(), 把选出的数据按性别记总数。
survived_sex长这个样子

dead_sex 同理

然后用
df = pd.DataFrame([survived_sex,dead_sex]) 把两个数据框合成一个数据框
df.index = ['Survived','Dead'] 并且给它们加上行标签
df长这样

最后通过df.plot(kind='bar',stacked=True, figsize=(15,8)) 把数据用重叠的柱状图画出来
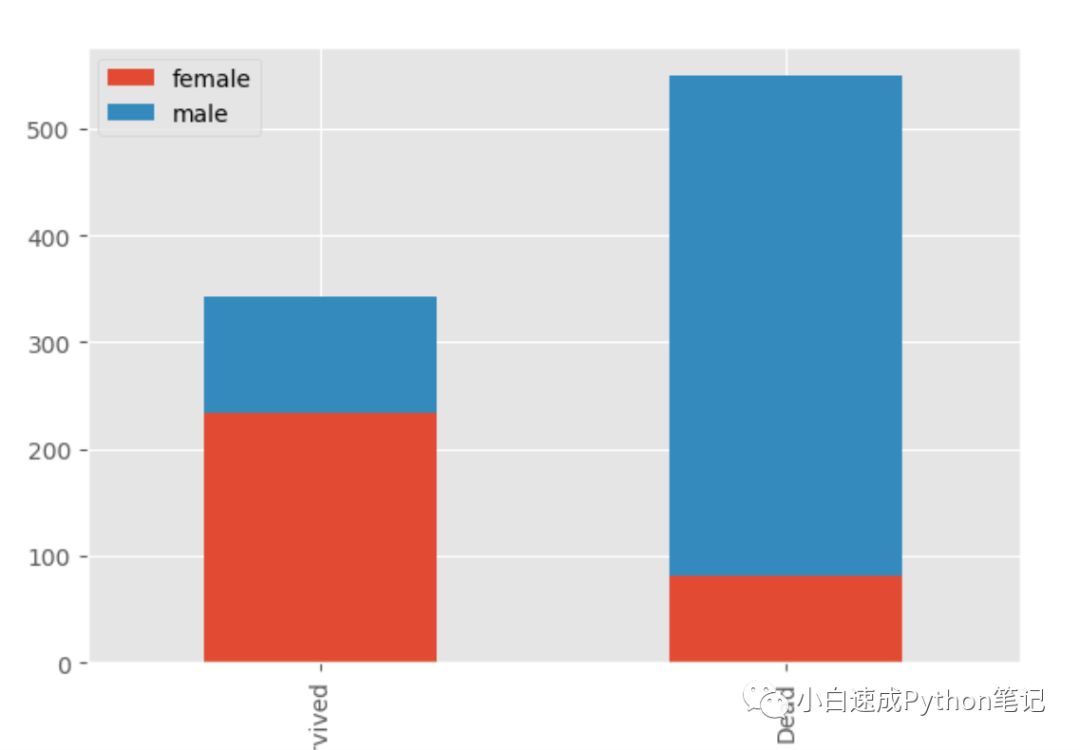
大家可以看到,男同胞死亡率高很多,女同胞幸存几率更大。
接下来我们用matplotlib看看不同年龄的幸存率。
figure = plt.figure(figsize=(15,8))plt.hist([data[data['Survived']==1]['Age'], data[data['Survived']==0]['Age']], stacked=True, color = ['g','r'],
bins = 30,label = ['Survived','Dead'])plt.xlabel('Age')plt.ylabel('Number of passengers')plt.legend()
这个包是另一种画图思路,先通过第一行代码创建一个画板,然后一件一件的往上面画东西。
用plt.hist先画重叠直方图。
data['Survived']==1]['Age'] 代表统计不同年龄活下来的数量。
data['Survived']==0]['Age'] 代表统计不同年龄死亡的数量。
然后用plt.xlable和plt.ylable写用哪些数据做x和y轴。
最后写legend,显示标签。大家感兴趣的话这有个链接教matplotlib。
#/plotting/advanced.html
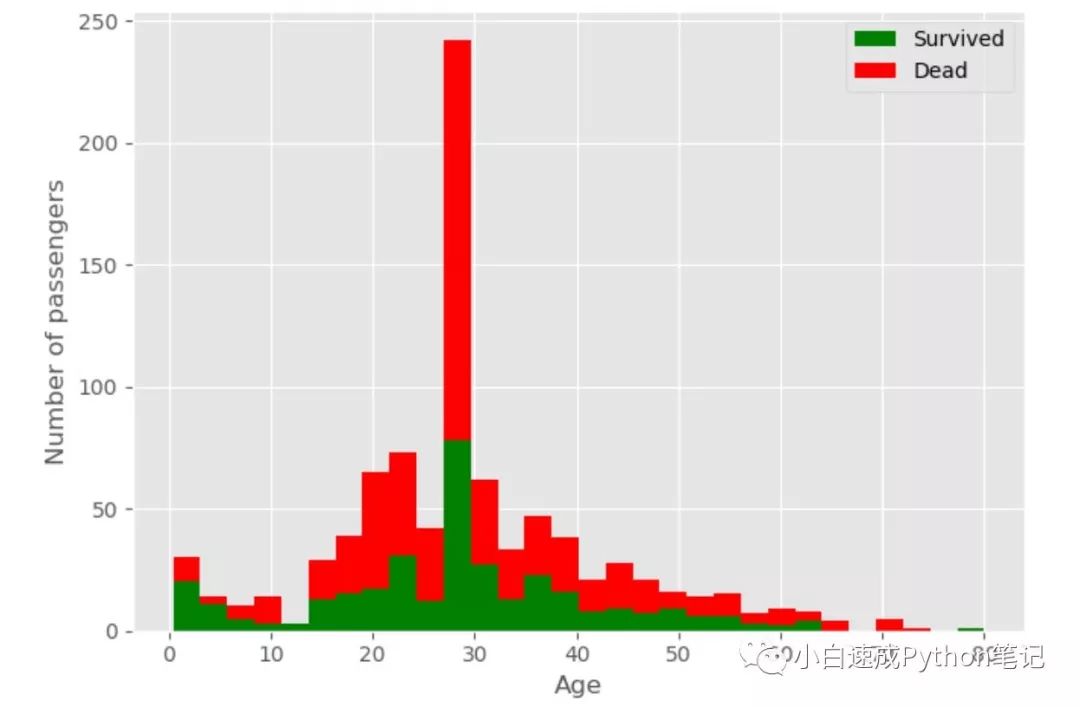
这次很明显未成年人活下来的几率更大。大家都是好人啊。
再看一个船票价格和生还率的关系,还是matplotlib
figure = plt.figure(figsize=(15,8))plt.hist([data[data['Survived']==1]['Fare'],data[data['Survived']==0]['Fare']], stacked=True, color = ['g','r'],
bins = 30,label = ['Survived','Dead'])plt.xlabel('Fare')plt.ylabel('Number of passengers')plt.legend()
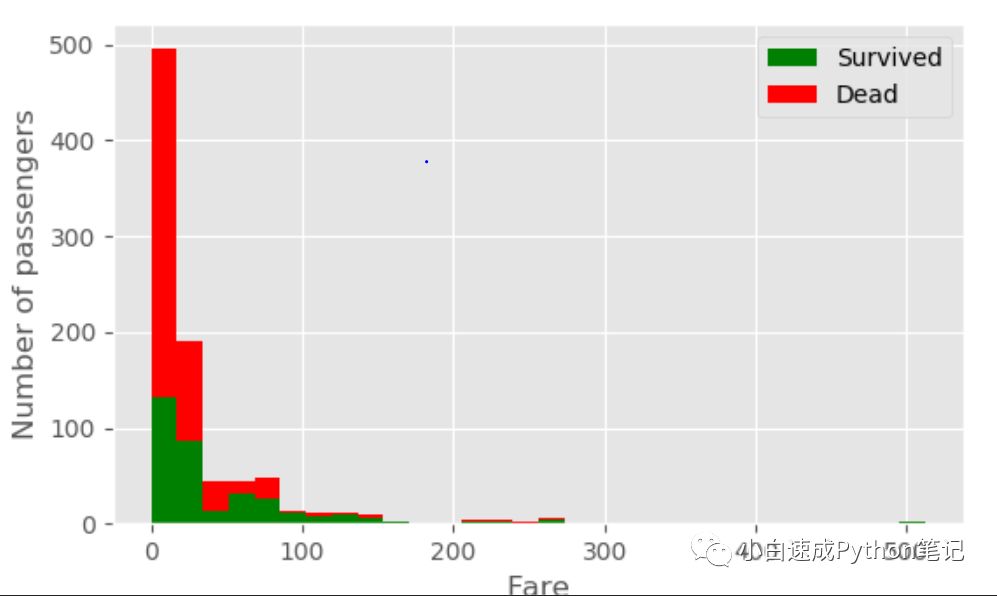
社会很现实 越有钱生存几率越大
最后再看一组Embark的数据,说不定登船口也决定了乘客的位置是不是可以更好地逃生
又回到pandas了。
survived_embark = data[data['Survived']==1]['Embarked'].value_counts()dead_embark = data[data['Survived']==0]['Embarked'].value_counts()df = pd.DataFrame([survived_embark,dead_embark])df.index = ['Survived','Dead']df.plot(kind='bar', stacked=True, figsize=(15,8))
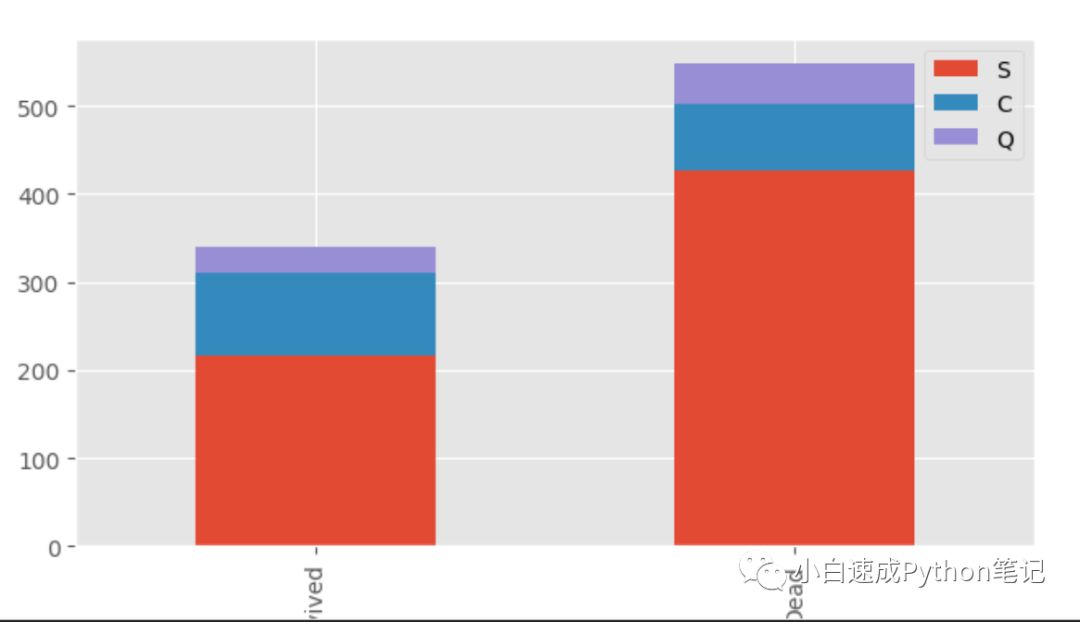
大家看在S和Q登船的死亡率更高一些,C口的生还率则高一些
然后我们大胆的猜测不同价格的票登船口不一样,有钱人应该在C登船(matplotlib)
所以我们看看不同登船地点的平均票价
ax = plt.subplot()ax.set_ylabel('Average fare')data.groupby('Embarked').mean()['Fare'].plot(kind='bar',figsize=(15,8), ax = ax)
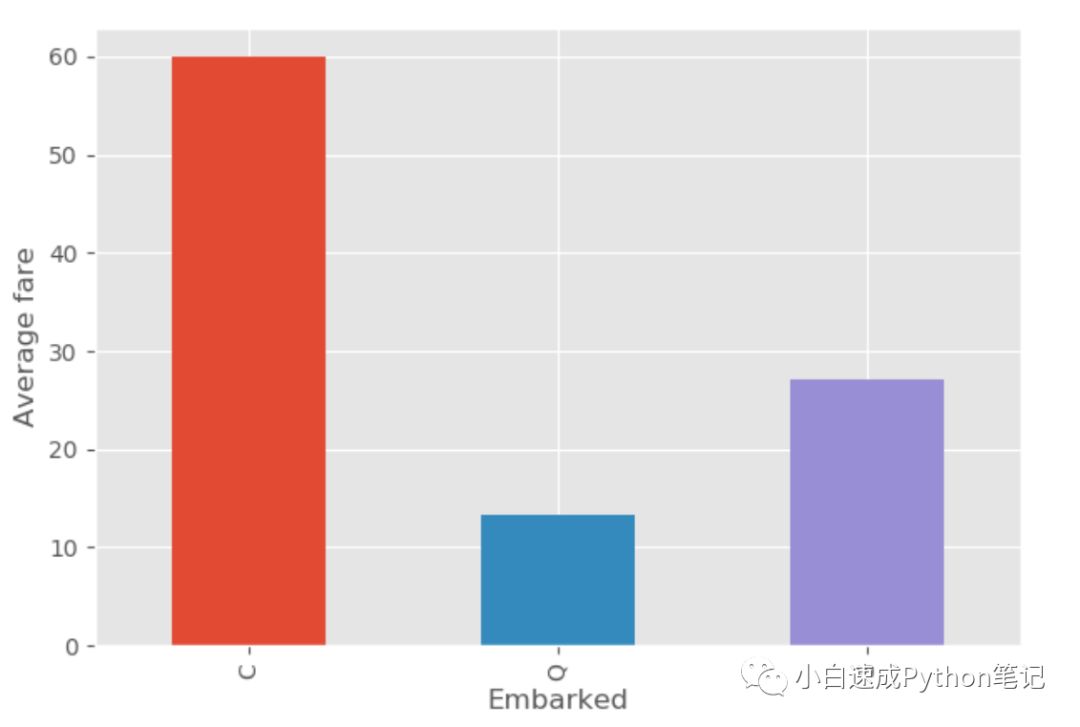
果然,有钱就是好啊
其实Embarked, Fare, Cabin, Pclass 应该都是和价格相关的。大家也可以画更多的图来观察数据的相关性。
数据清理阶段
上一步的画图中,是让人去看图分析
在这一步我们要把数据转换成纯数字的数据
因为计算机只能看懂数字,因为只有计算机可以看懂数据了,才可以由计算机代替人去海量分析数据之间的关系。
首先我们导入原始数据,相信大家都有经验啦, 不要忘记替换文件目录
train = pd.read_csv('C:/Users/Razer/Downloads/train.csv')test = pd.read_csv('C:/Users/Razer/Downloads/test.csv')
然后去掉train里的Survived数据,使train和test保持一致,因为test是没有Survived这一列的,列数如果不同,就不能合并数据框。
train.drop('Survived', 1, inplace=True)
创建新的变量 combined, 把两个文件的数据放到一起,方便处理
在第一行代码里,合并数据框的操作是用.append函数做到的
在第二行里我们.reset_index为combined创建一个新的序列号,从数字1到最后,因为刚合并完的序号是乱的
在第三行里我们删除老的序列号。
combined = train.append(test)combined.reset_index(inplace=True)combined.drop('index', inplace=True, axis=1)
在这里要向大家介绍一点新知识,自己创建函数
举个例子,第二种方法,刚才的几行代码也可以这样写,不要忘了改目录哈
def get_combined_data():
train = pd.read_csv('C:/Users/Razer/Downloads/train.csv')
test = pd.read_csv('C:/Users/Razer/Downloads/test.csv')
train.drop('Survived', 1, inplace=True)
combined = train.append(test)
combined.reset_index(inplace=True)
combined.drop('index', inplace=True, axis=1)
return combined
直接按回车,好啦,我们自己的函数定义好啦
我先解释一下这个函数的代码
第一行首先用def表示我们要写函数啦,def后面蓝色的代表我们想要的函数的名字,在后面的括号里可以设置函数可以用到的变量,这个我们后面还有例子要说明。
然后看到最后一行return combined, 意思是我们通过这个函数会得到combined这个值。
运行函数的话 我们要输入函数的名字
get_combined_data()
之后Python Console会返回所有的数据
这个时候我们要比较一下两种方法的区别
第一种方法: 创建了三个新变量 train, test, combined。并且他们是全球变量(global variable), 意思是任何函数都可以使用global函数调用他们,之后会看到。
第二种方法:没有创建任何全球变量,这种方法创建的是本地变量(local variable)。这种变量只能在函数运行中使用,并不会产生全球变量。
所以说我们刚才运行函数,并没有想第一种方法一样产生新的全球变量train, test 和combined, 它只返回一个结果。
怎么获得全球变量呢? 机智如我
combined = get_combined_data()
好啦,直接把函数结果赋值给一个新的全球变量就好
可以用head看一下
combined.head()
是不是很爽,哈哈哈哈
接下来我们继续搞数据,我们接下来会用到Python的列表,元组,字典这三个东西,建议大家看一下“菜鸟教程”里的这三个部分,只看这三个就好。地址在这里
#/python3/python3-list.html
现在我们想把名字转化成更有意义的类别,因为名字里的敬称代表着不同的社会地位,我们通过敬称,把人做一个分类,注意这里用到了全球变量combined, 我们用global使用它。
def get_titles():
global combined
# 第一步
combined['Title'] = combined['Name'].map(lambda ame:name.split(',')[1].split('.')[0].strip())
# 第二步
Title_Dictionary = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Master" : "Master",
"Lady" : "Royalty"
}
# 第三步
combined['Title'] = combined.Title.map(Title_Dictionary)
第一步,提取名字里的敬称
先看等号左边,combined['Title']这里的意思是为combined这个数据框创建一个新的列Title
等号右边我们先看后面括号里的内容,lambda是一个匿名函数。是的它也是一个函数,是简化版的,没有名字,只能写一行代码实现简单的功能。
在lambda这个小函数里,我们给它的本地变量起名叫name,这个本地变量叫什么都可以,你起名叫shit也可以运行。这个本地变量代表的是括号外的combined数据框name这一列的每一个值。
所以说等号右边就是会把着combined数据框里每一个name按照lambda里面的小小的匿名函数运行一遍,并且用.map赋值。
这个函数是干嘛的呢?它用.split函数把每个字符串string(也就是我们的每一个name)按照“,”分裂成包含n个元素。
例如 “ba,ba” 会变成 ['ba', 'ba'] 包含两个元素的列表。我们的名字分裂后里第二个的元素一般是名字的敬称,小姐姐 Miss, 之类的。我们用[1]这个表达式选出刚才列表里的第二个元素,然后再用split('.')[0]删除敬称里面的“.” 再用.strip()删掉除了字符之外的东西比如字符两头的空格。
最后,等号左右两边连在一起,我们牛逼哄哄的用一行代码把为combined数据框创建了新的列Tittle, 并且用敬称赋值。
第二步 , 对敬称做一个分类
我们创建了一个字典,这个字典就像一个目录,告诉Python每个敬称,代表什么样的社会地位,我们这里有工作人员,由贵族,有老百姓什么的。
第三步 我们把title里的敬称替换成新的分类。
#号在Python里是备注的意思,并不会执行
好啦, 大家运行一下
get_titles()
这个函数会直接对我们的combined全球变量做出更改。
大家可以再用head查看一下,产生了一个新的列 Title.
combined.head()
接下来我们要填充缺失的年龄,大家可以用.info看一下
#()
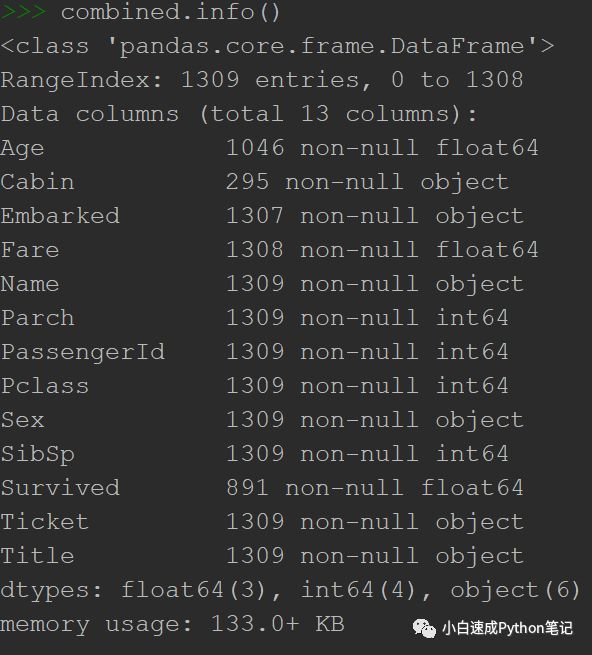
看起来缺失了263个年龄
不怕不怕,我们决定统计一下按照性别sex, 票的等级Pclass, 社会地位Title, 把所有人分成不同的小组,然后按照缺失信息的那个人所在组的年龄中位数指定为他们的年龄。
grouped = combined.groupby(['Sex','Pclass','Title'])grouped_median = grouped.median()
然后直接打出看看
grouped_median
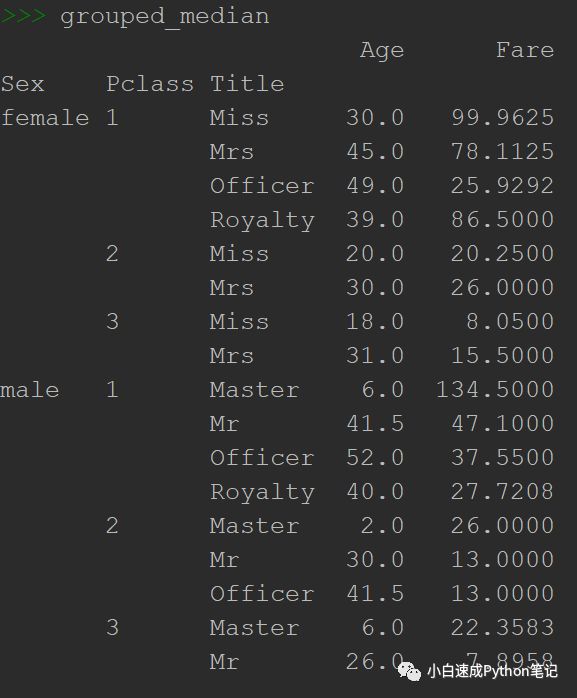
我们接下来就要为缺失值制定年龄啦
我们接下来要用到循环概念,大概是对一组数据中的每一个值做重复的事情。
没接触过这个概念的可以先看一下“菜鸟教程”的条件控制和循环 这两页
这是条件控制的链接
#/python3/python3-conditional-statements.html
好啦,上替换缺失值的代码
# 第一层def process_age(): global combined
# 第二层
def fillAges(row, grouped_median):
if row['Sex']=='female' and row['Pclass'] == 1:
if row['Title'] == 'Miss':
return grouped_median.loc['female', 1, 'Miss']['Age']
elif row['Title'] == 'Mrs':
return grouped_median.loc['female', 1, 'Mrs']['Age']
elif row['Title'] == 'Officer':
return grouped_median.loc['female', 1, 'Officer']['Age']
elif row['Title'] == 'Royalty':
return grouped_median.loc['female', 1, 'Royalty']['Age']
elif row['Sex']=='female' and row['Pclass'] == 2:
if row['Title'] == 'Miss':
return grouped_median.loc['female', 2, 'Miss']['Age']
elif row['Title'] == 'Mrs':
return grouped_median.loc['female', 2, 'Mrs']['Age']
elif row['Sex']=='female' and row['Pclass'] == 3:
if row['Title'] == 'Miss':
return grouped_median.loc['female', 3, 'Miss']['Age']
elif row['Title'] == 'Mrs':
return grouped_median.loc['female', 3, 'Mrs']['Age']
elif row['Sex']=='male' and row['Pclass'] == 1:
if row['Title'] == 'Master':
return grouped_median.loc['male', 1, 'Master']['Age']
elif row['Title'] == 'Mr':
return grouped_median.loc['male', 1, 'Mr']['Age']
elif row['Title'] == 'Officer':
return grouped_median.loc['male', 1, 'Officer']['Age']
elif row['Title'] == 'Royalty':
return grouped_median.loc['male', 1, 'Royalty']['Age']
elif row['Sex']=='male' and row['Pclass'] == 2:
if row['Title'] == 'Master':
return grouped_median.loc['male', 2, 'Master']['Age']
elif row['Title'] == 'Mr':
return grouped_median.loc['male', 2, 'Mr']['Age']
elif row['Title'] == 'Officer':
return grouped_median.loc['male', 2, 'Officer']['Age']
elif row['Sex']=='male' and row['Pclass'] == 3:
if row['Title'] == 'Master':
return grouped_median.loc['male', 3, 'Master']['Age']
elif row['Title'] == 'Mr':
return grouped_median.loc['male', 3, 'Mr']['Age']
#第二层里运行第三层也就是我们刚写的fillAge函数
combined.Age = combined.apply(lambda r : fillAges(r, grouped_median) if p.isnan(r['Age'])
else r['Age'], axis=1)
这一段有意思的地方是函数里面套着函数,循环里面套着循环。呵呵呵。感受一下Python版本的盗梦空间。(好巧,泰坦尼克号也是小李子主演)
这里还要注意Python代码运行时候是先从外到里,然后才是从上到下。
区分从外到里的方法就是看代码的缩进也就是TAB键,没向里一层,就多用一次TAB。
注意了第一步也就是最外层是 def process_age(): 这是整个函数的总起。没有TAB
然后TAB 一下 到第二层 我们定义了一个新函数 fileAge,但是它现在并没有运行。我们在第二层最后的一行代码中调用了它,我觉得就像是进入了第三层。
我们先讲讲fileAge这个函数,
它定义了两个本地变量,row 和 grouped_median,注意这里名字是什么无所谓,这里的本地变量grouped_median和我们上一步的全球变量grouped_median他们有本质的区别。但是我们一会会把外面的全球变量grouped_median的值赋给里面的本地变量grouped_median。
在这里函数里利用条件控制(大家都看了吧就是if和elif)把每一行数据划分到不同的小组里并且按照上一步的中位数赋值。这里用的新函数是.loc 和Excel里的VLOOKUP函数非常相似。大概就是设定条件搜索结果的用法。
然后讲讲最后一行代码
等号左边选出combined数据框里的Age列,
右边用.apply给combined数据框里每一行的age赋值。
最后讲讲lambda这个匿名循环
它的变量叫r, 也就是combined数据框的每一行,数据框在循环里以行为一个单位。
好,选出一行,然后if这一行没有值,就调用我们写的fileAge来填充空值,我们调用fileAge的时候,在小括号里设定了(r, grouped_median),r就是每一行,grouped_median这里指的是我们的全球变量grouped_median。这里就是指定了fillAges(row, grouped_median)里面的row和grouped_median两个本地变量,等于(r, grouped_median)的值。
else if 其他情况也就是已经有年龄的,就赋值它这一行原本的年龄。global combined
好啦,运行一下
process_age()
这时候再试一次.info
#()
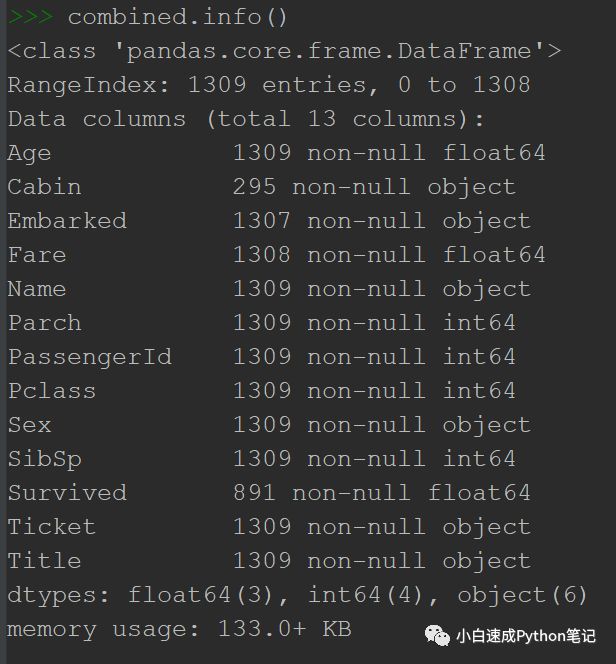
很好,很成功的填好了Age的所有空值。
接下来我们删除姓名这列没什么价值的列
并且把社会地位Title变成虚拟变量dummy variables,用.concat加入到combined数据框里。
然后再删除Title
举例dummy variables 大概就像下图的调查问卷
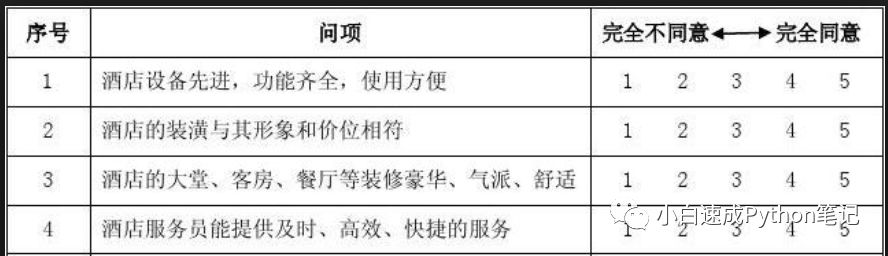
在右边选值的地方有五个列, 从不同意到同意,每一行这五个值只能选一个。
在python的世界里,选了就是数字一,没选就是数字0.
我们的社会地位Title转换完了在combined数据框里长这样,大家可以对比理解一下
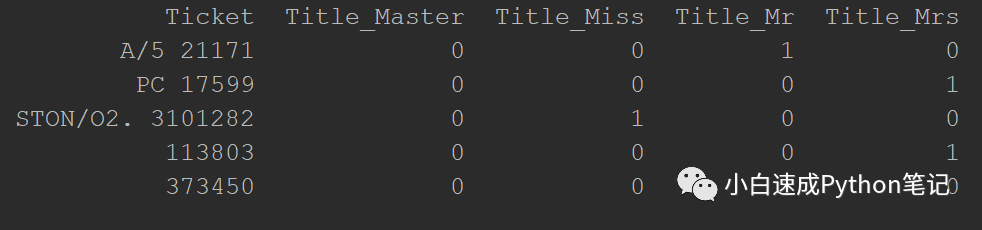
def process_names():
global combined
# we clean the Name variable
combined.drop('Name',axis=1,inplace=True)
# encoding in dummy variable
titles_dummies = pd.get_dummies(combined['Title'],prefix='Title')
combined = pd.concat([combined,titles_dummies],axis=1)
# removing the title variable
combined.drop('Title',axis=1,inplace=True)
好啦, 别忘了运行
process_names()
这个时候不用我说,相信大家也会用shape, info, head,describe 来看一下我们的数据了吧。
接下来给缺失的Fares赋值一个平均数,因为只缺一个,就不用很麻烦了。
combined.Fare.fillna(combined.Fare.mean(), inplace=True)
然后是Embarked的空值填充,赋值S,就缺两个值,所以随便选的,因为S比较多。
然后把Embarded也转换成虚拟变量,加入combined数据框里。
def process_embarked():
global combined combined.Embarked.fillna('S', inplace=True)
# dummy encoding
embarked_dummies = pd.get_dummies(combined['Embarked'],prefix='Embarked')
combined = pd.concat([combined,embarked_dummies],axis=1)
combined.drop('Embarked',axis=1,inplace=True)
运行
process_embarked()
接下来把没有空缺的Cabin留首字母, 空缺的Cabin的值转化成“U” 表示unknow,
def process_cabin():
global combined
# replacing missing cabins with U (for Uknown)
combined.Cabin.fillna('U', inplace=True)
# mapping each Cabin value with the cabin letter
combined['Cabin'] = combined['Cabin'].map(lambda c : c[0])
# dummy encoding ...
cabin_dummies = pd.get_dummies(combined['Cabin'], prefix='Cabin')
combined = pd.concat([combined,cabin_dummies], axis=1)
combined.drop('Cabin', axis=1, inplace=True)
然后运行
process_cabin()
接着把combined数据框的sex列里面的female和male两个字符值换成数字0,1.
combined['Sex'] = combined['Sex'].map({'male':1,'female':0})
把舱位等级Pclass换成虚拟变量,
def process_pclass():
global combined
# encoding into 3 categories:
pclass_dummies = pd.get_dummies(combined['Pclass'], prefix="Pclass")
# adding dummy variables
combined = pd.concat([combined,pclass_dummies],axis=1)
# removing "Pclass"
combined.drop('Pclass',axis=1,inplace=True)
运行
process_pclass()
下一步,保留Ticket的前缀,
这里用到.replace删掉Ticket里没意义的符号,
然后有map,lambda,strip配合帮助清理ticket号码前后的空格
然后是新知识filter函数
filter帮助过滤我们需要的值,他的小括号里有两个值,第一个是条件,第二个是将被过滤的对象
如果条件满足就会返回“Ture", 不对就返回"False"。我们这里的条件是lambda匿名函数。
在我们这个匿名函数里,ticket的值是数字的话,就通过.isdigit返回 "Ture",但是我们前面有个not, 所以会再反转一下,再变回 “False”。反之亦然。
所以总的来说,filter会帮助我们筛选出带有字母的票号,只有数字的会设为空值。
对于清理完之后所有空值的我们指定值“XXX” 表示不知道
接着老套路,创建Ticket虚拟变量
def process_ticket():
global combined
# a function that extracts each prefix of the ticket, returns 'XXX' if no prefix (i.e the ticket is a digit)
def cleanTicket(ticket):
ticket = ticket.replace('.','')
ticket = ticket.replace('/','')
ticket = ticket.split()
ticket = map(lambda t : t.strip(), ticket)
ticket = filter(lambda t : not t.isdigit(), ticket) x=list(ticket)
if len(x) > 0:
return x[0]
else:
return 'XXX'
# Extracting dummy variables from tickets:
combined['Ticket'] = combined['Ticket'].map(cleanTicket)
tickets_dummies = pd.get_dummies(combined['Ticket'], prefix='Ticket')
combined = pd.concat([combined, tickets_dummies], axis=1)
combined.drop('Ticket', inplace=True, axis=1)
运行
process_ticket()
我们接着处理Parch和SibSp, 我们把他们合为一体变成Family Size
并且直接生成虚拟变量
def process_family():
global combined
# introducing a new feature : the size of families (including the passenger)
combined['FamilySize'] = combined['Parch'] + combined['SibSp'] + 1
# introducing other features based on the family size
combined['Singleton'] = combined['FamilySize'].map(lambda s: 1 if s == 1 else 0)
combined['SmallFamily'] = combined['FamilySize'].map(lambda s: 1 if 2<=s<=4 else 0)
combined['LargeFamily'] = combined['FamilySize'].map(lambda s: 1 if 5<=s else 0)
运行
process_family()
好啦到此为止,我们数据准备工作完成啦。总计68列。
组建机器学习模型
首先简单了解下机器学习。机器学习是人工智能领域的概念。
它可以分为监督学习,无监督学习,半监督学习,增强学习。
举例:
监督学习,我们这次就是监督学习,在train文件里有乘客信息和是否生还的结果,我们就要观察train文件里面不同类型的乘客的生还可能性。来推测test文件里乘客的生还结果。
大概就是给定两个结果,存活或者死亡,把所有人分到这两个类别里。只要这两种结果
无监督学习,直接给所有乘客的信息,让电脑自动把他们按相似的特征分成不同的组。例如,我和吴彦祖被分到一起,代表我们是比较相似的人。与无监督学习不一样的是,这里并没有固定要分的结果,最后分成的组的数目是不一定的。
半监督学习, 前两者的结合。
增强学习,大概就是像训练小动物一样,通过奖罚,让它们知道怎么做。比如当红炸子鸡,对抗网络。
监督学习有很多模型我们今天要用的是随机森林,随机森林是基于决策树的。
决策树大概长这样,从上往下每个节点(方块)有不同的选择(线),最下面产生n个决策也就是Leaf(叶子),(椭圆)。 顺下来,很容易就得知一个西瓜的好坏。
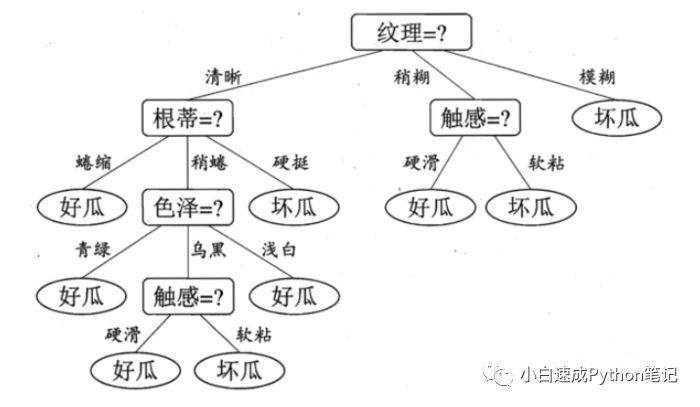
随机森林是决策树的增强版本,它有两个随机过程构成。核心思想是“三个臭皮匠赛过诸葛亮”。
第一个随机过程,在原始数据集中,有放回的随机抽样组成很多个新的数据集。这就代表了每个新的数据集中可能有重复的原始数据集的某条数据,因为是有放回的抽样。重点是每个新的数据集都是不相同的,就可以理解为我们用有限的数据,创造出了更多的数据。增大了样本量。(P.S.学过统计的同学可以联想下中心极限定理,我心虚的感觉它们有异曲同工之妙)
第二个随机过程,是我们在对每个新的数据集构建决策树的时候,要在每个分叉的节点选择用哪个特征来决策。这个选择特征过程是随机的。比如总计有十个特征,在遇到新的分差节点时,我们设定在十个里面随机选出五个,然后在设定某种策略(比如信息增益),在这五个中随机选出一个特征作为这个节点的特征。
所以通过两个随机过程我们得到了很多不一样的决策树,然后我们就可以以统计一下这些树的结果(少数服从多数之类的),对每个样本进行预测。
好啦,回到代码部分。
我们要干的第一件事就是评估一下我们刚才68列特征的对预测结果准确性的好坏。
from sklearn.pipeline import make_pipelinefrom sklearn.ensemble import RandomForestClassifierfrom sklearn.feature_selection import SelectKBestfrom sklearn.cross_validation import StratifiedKFoldfrom sklearn.grid_search import GridSearchCVfrom sklearn.ensemble.gradient_boosting import GradientBoostingClassifierfrom sklearn.cross_validation import cross_val_score
加载一堆包,有warning不用太担心。
然后我们创建以下几个全球变量。
targets是我们验证结果准确度的正确答案
train是有答案的combined数据框的前891个
test是891个之后的样本,也是我们最终要预测并提交的结果的样本
train0 = pd.read_csv('C:/Users/Razer/Downloads/train.csv')targets = train0.Survivedtrain = combined.head(891)test = combined.iloc[891:]
接着加载包,并且用RandomForestClassifier和.fit创建一个分类器clf,我觉得clf就是个简易版的随机森林模型。给我们筛选特征的时候先用一下。
from sklearn.ensemble import RandomForestClassifierfrom sklearn.feature_selection import SelectFromModelclf = RandomForestClassifier(n_estimators=50, max_features='sqrt')clf = clf.fit(train, targets)
然后我们通过clf分类器和画图来看一下我们68个特征对优化函数的重要性
第一行代码创建的空数据框features
第二行和第三行给数据框赋值两列,feature(train的列名)和importance重要性(通过)
features = pd.DataFrame()features['feature'] = train.columnsfeatures['importance'] = clf.feature_importances_features.sort_values(by=['importance'], ascending=True, inplace=True)features.set_index('feature', inplace=True)features.plot(kind='barh', figsize=(20, 20))
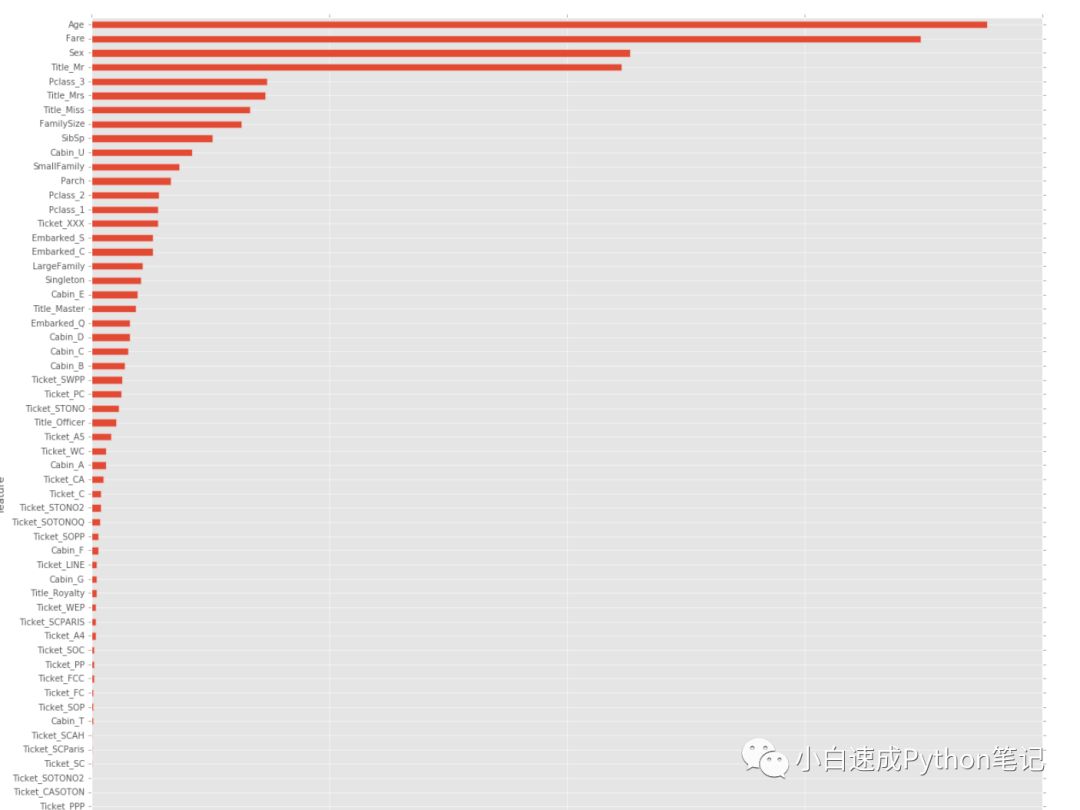
可以清楚地看到,Sex, PassengerId, Fare, Title, 等等这些比较重要。
接下来我们用SelectFromModel选出排名高于重要性平均值的特征,
然后用.transform创建只包含这些特征的train_reduced变量
model = SelectFromModel(clf, prefit=True)train_reduced = model.transform(train)
我们来看看train_reduced
train_reduced.shape
(891, 14)只剩下14列了。
然后创建一个计算准确性的函数,一会测试我们结果准确度用,用到了cross_val_score函数,通过设定CV参数把要测试的数据集combined 分成五个小数据集,然后互相对比分析,用平均值代表准确度。大家感兴趣的可以查一下cross-validation strategies。
def compute_score(clf, X, y, scoring='accuracy'):
xval = cross_val_score(clf, X, y, cv = 5, scoring=scoring)
return np.mean(xval)
接下来设置我们随机森林模型的参数
parameters = {'bootstrap': False, 'min_samples_leaf': 3, 'n_estimators': 50, 'min_samples_split': 10, 'max_features': 'sqrt', 'max_depth': 6}
model = RandomForestClassifier(**parameters)model.fit(train, targets)
具体的参数设置技巧,大家可以查看以下网页
#/blog/2015/06/tuning-random-forest-model/
然后运行函数看看成果
compute_score(model, train, targets, scoring='accuracy')
结果还是不错的。准确率有百分之八十多

接下来我们用这个模型来预测test里的数据,不要忘记改文件目录哈,一个输入的,一个输出的。
输出地址就是你想创建结果的地址,最后的文件名可以自己随便设立。。
output = model.predict(test).astype(int)df_output = pd.DataFrame()aux = pd.read_csv('C:/Users/Razer/Downloads/test.csv')df_output['PassengerId'] = aux['PassengerId']df_output['Survived'] = outputdf_output[['PassengerId','Survived']].to_csv('C:/Users/Razer/Downloads/output5.csv',index=False)
之后大家就可以去Kaggle提交成绩啦。
恭喜各位。我用同样的模型拿到了0.80861的准确率,在9000多参赛者里是排名前10%的分数。
最后要说的是,这个Titanic是入门的练手案例,用来熟悉机器学习的方法,大家胜负心不用太强,这个分数还是可以的。
最重要的是本笔记假象的读者是完全不会python的,希望大家看完后对机器学习和python有更深入的理解
本文内容转载自网络,来源/作者信息已在文章顶部表明,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



