

Python培训
400-996-5531
400-996-5531
今天给大家带来我的python爬虫学习路线,供大家参考!
第一步,学会自己安装python、库和你的编辑器并设置好它
我们学习python的最终目的是要用它来达到我们的目的,它本身是作为工具的存在,我们一定要掌握自己的工具的各类设置,比如安装、环境配置、库的安装,编辑器的设置等等。
当然也可以用比如Anaconda来管理你的版本和各种库!

第二步、学会一些基础的模块
我们有目标网址,怎么写爬虫呢?这个时候,建议大家可以找一些简单爬虫的视频或者文章,跟着老师一起写代码,先感受一下爬虫是怎么一步一步的在你的手里完成的!
当然这里不是说你照着老师的代码敲一遍就算学会了,个人认为,这里你最少要做三步:
l 所有你不知道的库、函数、语法都需要记录下来,自行学习掌握,并在以后的爬虫中继续这个步骤,很重要
l 要学会老师的思路。比如基本所有的教程并不是拿到url就开始写代码了,都有自己的分析过程,而思路在爬虫中占到很大一部分的比重,有了思路,写代码就不难了
l 先模仿在独立完成。先跟着老师做一些简单的爬虫,然后思路和代码都掌握以后,就可以尝试自行查找类似的项目去独立完成一个爬虫了!
l 推荐基础模块:re,requests,time等,自定义函数、类等语法以及报头、cookie的写入等等也需要了解
到这里,你应该已经掌握了python的基础模块并写出了你的简单爬虫,那么可以进行下一个步骤的学习了

第三步、学习各种表达式,并精通1-2种!
学会了如何爬取网页内容之后,你还需要学会进行信息的提取。事实上,信息的提取你可以通过表达式进行实现,同样,有很多表达式可以供你选择使用,常见的有正则表达式、XPath表达式、BeautifulSoup(bs4)等,这些表达式你没有必要都精通,同样,精通1-2个,其他的掌握即可,在此建议精通掌握正则表达式以及XPath表达式,其他的了解掌握即可。正则表达式可以处理的数据的范围比较大,简言之,就是能力比较强,XPath只能处理XML格式的数据,有些形式的数据不能处理,但XPath处理数据会比较快,而且以后你学习爬虫框架也会用到xpath。
第四步、深入掌握抓包并分析提取需要的内容
在我们练习的过程中,会经常碰到有反爬措施的网站,而这些网站最常使用的措施就是隐藏数据,那么这时我们就要学会使用抓包分析,推荐大家一定要精通浏览器的开发者工具以及fiddler抓包工具,当然其他抓包工具或者抓包插件也可以,没有特别要求。

第五步、精通爬虫框架
当你学习到这一步的时候,你已经入门了。
这个时候,你可能需要深入掌握一款爬虫框架,因为采用框架开发爬虫项目,效率会更加高,并且项目也会更加完善。
同样,你可以有很多爬虫框架进行选择,比如Scrapy、pySpider等等,一样的,你没必要每一种框架都精通,只需要精通一种框架即可,其他框架都是大同小异的,在此推荐掌握Scrapy框架.
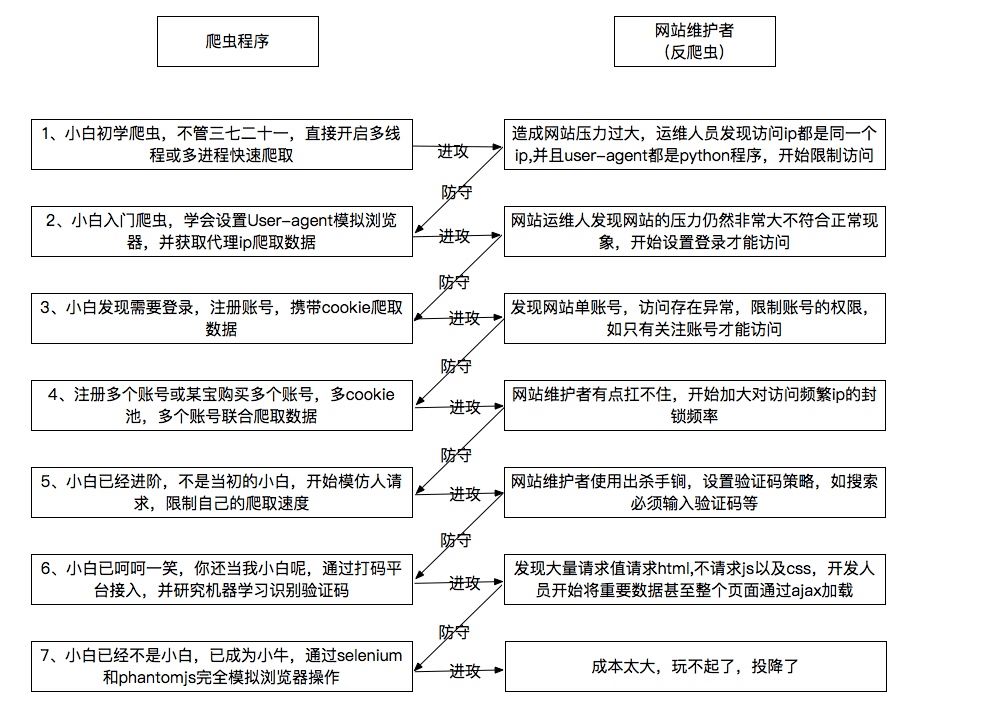
第六步、反爬的学习和精通
常见的反爬策略主要有:
IP限制
UA限制
Cookie限制
资源随机化存储
动态加载技术
……
对应的反爬处理手段主要有:
IP代理池技术
用户代理池技术
Cookie池保存与处理
自动触发技术
抓包分析技术+自动触发技术
反爬以及反爬处理都有一些基本的套路,万变不离其宗,这些需要我们根据实际情况去选择使用
第七步、seleium+phantomjs(firefox/chorm)等工具的使用
有一些站点,通过常规的爬虫很难去进行爬取,这个时候,你需要借助一些工具模块进行,比如PhantomJS、Selenium等,所以,你还需要掌握PhantomJS、Selenium等工具的常规使用方法。
第八步、分布式爬虫技术的掌握
如果你已经学习或者研究到到了这里,那么恭喜你,相信现在你爬任何网站都已经不是问题了,反爬对你来说也只是一道形同虚设的墙而已了。
但是,如果要爬取的资源非常非常多,靠一个单机爬虫去跑,仍然无法达到你的目的,因为太慢了。
所以,这个时候,你还应当掌握一种技术,就是分布式爬虫技术,分布式爬虫的架构手段有很多,你可以依据真实的服务器集群进行,也可以依据虚拟化的多台服务器进行,你可以采用Scrapy+redis架构手段,将爬虫任务部署到多台服务器中就OK。
总结:
有人问:使用windows系统还是linux系统学习?其实,没关系的,由于Python的可移植性非常好,所以你在不同的平台中运行一个爬虫,代码基本上不用进行什么修改,只需要学会部署到Linux中即可。一般建议学习的时候使用Windows系统进行就行,之后部署到linux系统上就可以了。
以上是如果你想精通Python网络爬虫的学习研究路线,按照这些步骤学习下去,可以让你的爬虫技术得到非常大的提升。
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



