

Python培训
400-996-5531
400-996-5531
1、场景描述
在数据统计分析过程中,求累计值(总和)是常用的统计指标之一,市面上的各种流行数据库均支持的查询方式基本如下:
select sum(c) from table_name;
当数据量在小规模时,sum只是一瞬间的事情,让你感觉电脑真牛逼啊,我掰手指头要算半天的数,它居然可以这么快,下面是1万多条数据的字段求和,只用了8ms。
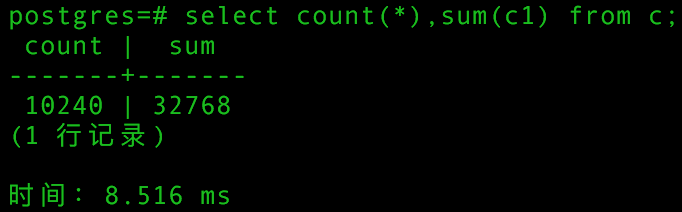
但是当数据量不断增长到一个量级时,比如说,先定个小目标:一亿条订单求总额,你可以尝试在常规的数据库上执行同样的语句需要多长时间。
在我的电脑上执行这样的查询,大约需要10s。

或者更大的量级,十亿、百亿、万亿?你一秒钟给我算出来,哈哈,电脑也算懵逼了。

采用分布式存储、分布式计算,是目前解决大规模计算的通用方法,让你吃100个馒头,估计一礼拜也吃不完,做慈善,一人一个分给班里的同学,几分钟就没了,吃不完的那个放学别走。
2、举栗说明
今天我们不讲分布式计算,先看看如何在单机上达到优的计算性能。
以下的示例,用python语言模拟求1亿条订单金额的平均值。
大家注意:我国小学生以后的课程都有python了,在未来编程是个基本技能。
2.1 首先用传统的For Loop方式
还是一亿条数据跑分
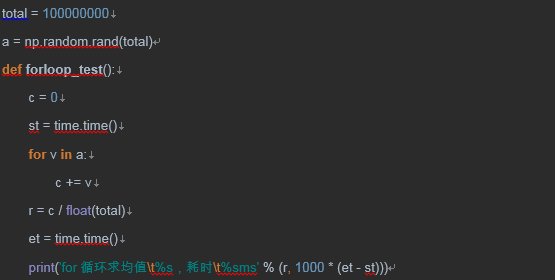
结果:
看来也不快啊,花了十几秒,python在没有特定优化的前提下,比Java,Go语言慢了不少。
2.2 内置 sum 函数上场
不过我们知道python有内置的sum函数,是不是会快一点?让我们来试试:

结果:
不到十秒,快了一点点,但还是不理想。
2.3 神兵numpy
听说有个numpy库,可以向量化(vectorization)执行各种运算,牵到台上看看:
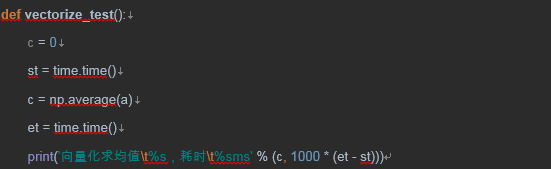
结果:
哎呀48毫秒,真心牛逼啊,足足快了几百倍,比Go、Java都快,不信你可以自己写个Go语言的版本对比一下。
2.3 没完
听说还有个叫numba的,看简写nb也很NB,要不把刚才的那些再跑一遍瞧瞧:

可以看出numba对For Loop的提升明显,对内置sum和numpy向量化影响不大。
来个对比图,一目了然(柱子越低性能越好):
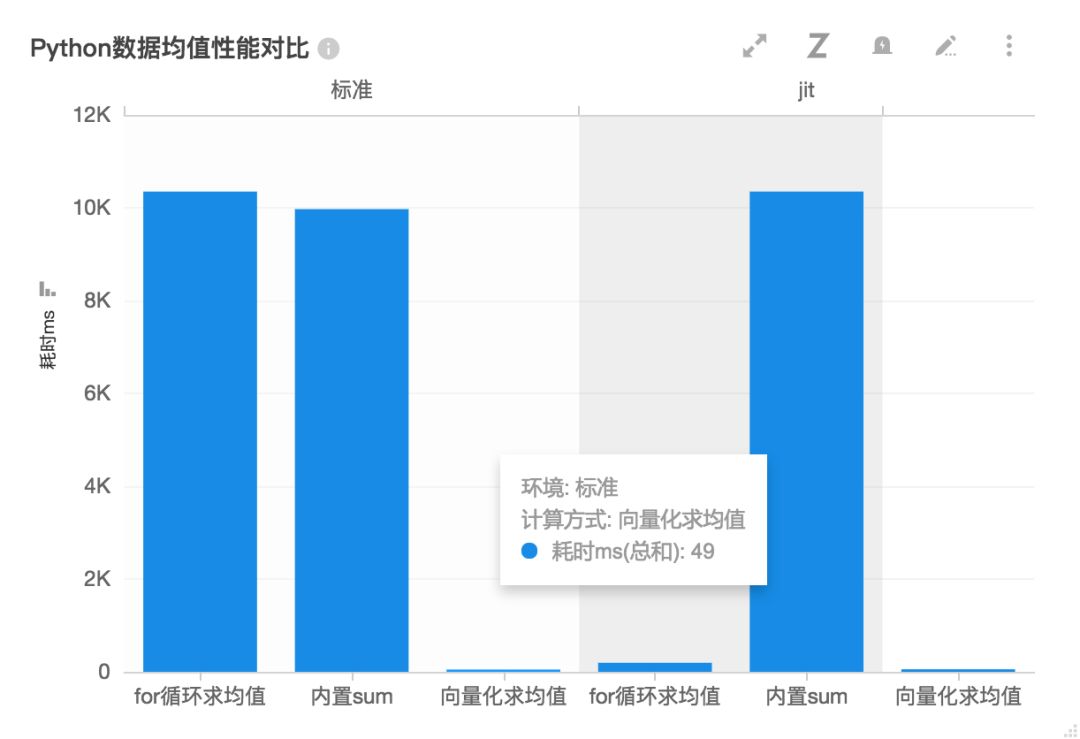
3、结论:磨刀不误砍柴工
现在有些数据库为了满足OLAP的需求,已经集成了向量化处理,通过测评,的确是显著提高了数据分析统计的性能,限于篇幅,今天不在此展开了。
Python numpy库主要提供:
ndarray,速度快且空间高效的多维array,可进行向量化算术操作和更高级推广应用能力。
标准数学函数,可快速执行整个array上的数据操作,而不需要写循环:
比如说arr = np.array([[1.,2.,3.],[4.,5.,6.]]),可以进行arr * arr,arr * 0.5,1/arr等运算,这些运算都是对array中的元素做相应的计算,即向量化的操作。
本文内容转载自网络,来源/作者信息已在文章顶部表明,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有




