

Python培训
400-996-5531
400-996-5531

图片源于:#/data-science-python-course/
近年来,Python已成为数据科学家的主要工具之一。本文概述了数据科学家及工程师们最常用的Python库。
1.1 Numpy

Numerical Python的简称,包含Python多维数组及矩阵操作方面的大量实用功能,用于矢量化数组运算,显著提高了执行速度,改善了性能。
1.2 Scipy

科学及工程软件库,包含线性代数、优化、集成、统计等功能。它的主要功能基于Numpy库,因此其中数组操作大量应用了Numpy库。
1.3 Pandas

包含Series及DataFrame两种特殊的数据结构,用于快捷的数据处理、聚合和可视化,尤其可以灵活处理缺失数据及数据分组。
2. 绘图及可视化
2.1 Matplotlib

Python中最常用的可视化库,由此可与MatLab、Mathematica等科学工具相提并论。它可以进行多种基本图形的可视化操作,并且包含标签、网格、图例等多种进行实体格式化的工具。
2.2 Seaborn
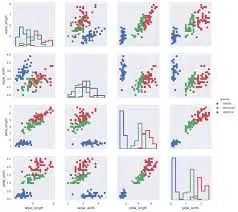
Seaborn主要用于统计模型的可视化,比如热力图等,可以对数据进行概述的同时描绘整体分布。Seaborn基于Matplotlib实现,并高度依赖于后者。
2.3 Bokeh
Bokeh库旨在进行交互式可视化,并且不依赖于Matplotlib,主要通过浏览器以“数据驱动文档”(Data-Driven Documents,d3.js)的形式演示。
2.4 Basemap
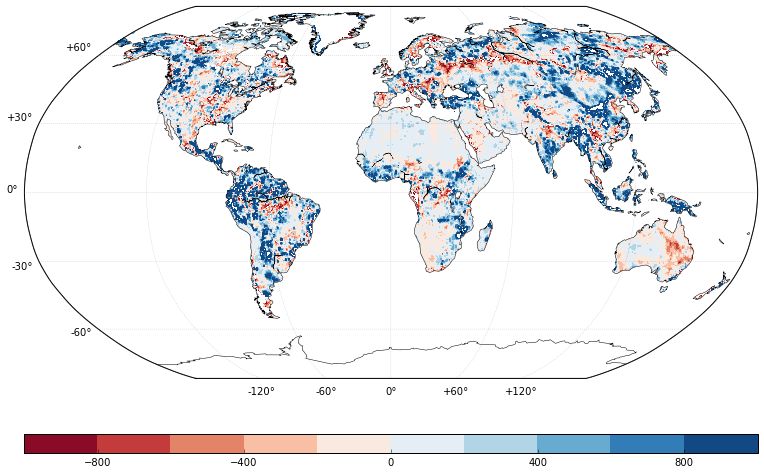
Basemap库通过使用Matplotlib中的坐标,为Matplotlib提供了简易地图的支持。Folium库在Basemap的基础上构建,可以制作交互式的Web地图,这类似于使用Bokeh创建的JavaScript小部件。
2.5 Plotly

Poltly库是一个基于Web、用于数据可视化的工具集,通过一系列API接口用于Python等编程语言的实现。plot.ly网站上展示了许多强大的图形。
2.6 NetworkX

NetworkX库用于复杂社会网络的分析。它可以处理标准数据格式及非标准数据格式,这使其具备高效性和可扩展性。
3. 机器学习
3.1 SciKit-Learn

SciKit-Learn为常见的机器学习算法提供了简洁而一致的界面,使得机器学习更容易应用于生产系统。它结合了高质量的代码和应用文档,具备易用性和高性能,事实上已成为使用Python进行机器学习的行业标准。
3.2 TensorFlow

TensorFlow库由谷歌工作人员开发,是一个数据流图计算的开源库,在机器学习方面的应用表现优越。主要特点是多层节点系统,可以在大型数据集上快速训练人工神经网络。这使得谷歌的语音识别和图像识别成为可能。
3.3 Theano

Theano库主要用于机器学习的需要,它定义了类似于Numpy的多维数组,以及数据操作和表达,在低级别操作上与Numpy结合紧密。Theano库经过了编译,优化了GPU和CPU的使用,在数据密集型计算方面性能更高,结果也更精确。
3.4 Keras

Keras库是用Python编写、用于高级界面中神经网络构建的开源库,具有可扩展性和高度模块化。它使用Theano或TensorFlow作为后端,目前微软正努力将CNTK(微软的认知工具包)作为新的后端。它设计简约,旨在通过构建紧凑型系统进行快速简单的实验。它的基本思想是基于层次的,其他一切都是围绕它们建立的。数据准备为张量形式,第一层负责张量输入,最后一层负责输出,模型置于两者之间。
4. 自然语言处理、数据挖掘及统计分析
4.1 NLTK

Natural Language Toolkit的简称,用于符号和统计自然语言处理等一般任务。NLTK包括许多功能,比如文本标记、分类、名称实体标识、建立显示句子间及句子间依赖性的语料树、词干、语义推理等。所有的构建块允许为不同的任务构建复杂的研究系统,比如情感分析、自动汇总等。
4.2 Gensim

Gensim是一个Python的开源库,为更高效地处理大文本数据而设计,实现了向量空间建模和主题建模。Gensim主要用于原始的、非结构化的数字文本处理,实现了层次Dirichlet过程(HDP)、潜在语义分析(LSA)、隐含Dirichlet分布(LDA)以及tf-idf、随机投影、word2vec、document2vec等算法,以分析语料集中重复文本出现的模式。所有算法都是无监督的,只需要输入语料库。
4.3 Scrapy

Scrapy是用于制作抓取程序的库,也被称为蜘蛛机器人,可用于网络中检索结构化数据,比如关联信息或URL。它的界面设计遵循著名的“不要重复自己”原则——它提示用户编写可重用的通用代码,以便构建和扩展大型爬虫。Scrapy的结构围绕Spider类构建,其内部封装了爬虫所遵循的指令集。
4.4 Pattern

Pattern库将Scrapy库和NLTK库的功能结合在一个大型库中,被设计为用于Web挖掘、自然语言处理、机器学习和网络分析的解决方案。其内部工具有网络爬虫;用于谷歌、推特和维基百科的API;解析树、情感分析等文本分析算法。
4.5 Statsmodels

Statsmodels库主要用于统计分析,通过应用统计模型估计方法进行数据探索,并进行推断分析。它使用的模型包括线性回归模型、广义线性模型、离散选择模型、时间序列分析模型等,还提供了大量统计分析方面的绘图功能。
END
参考文献:
#/blog/top-15-libraries-for-data-science-in-python/
#/machine-learning-library-python/
#/brandviews/upwork/15-python-libraries-data-science-01584664
注:图片源于网络。
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有




