

Python培训
400-996-5531
400-996-5531
爬虫原理:
网络抓取程序,俗称“爬虫”,爬虫的基本原理就是获取目标网址,下载网页,通过分析数据中的关键信息,获取资源。爬虫这个实际是翻译自英文的spider, 实际是蜘蛛的意思, 这个比喻很形象,蜘蛛在网上伺机而动,捕获食物。而我们的爬虫程序也就在因特网上爬取我们所需要的网络资源。
作用:
爬虫最重要的作用是充当搜索引擎,最简单的,我们上网浏览网页, 那我把网页都抓下来。建立了一个库,根据你搜的那个关键字(query),给你返回相应的数据,里面当然会根据相关度建立指标,比如比较权威的page rank,有那些权威的网站引用了,那个相关度就增高了。

百度和谷歌每天都会更新这个库。最早做搜索的时候,有种比较流氓的做法,就是去爬取竞争对手的搜出来的结果, 每个早期公司都会这个做,像之前百度会有参数叫谷歌参数,在搜索权重里面站的参数还比较重。

360做搜索就更厉害了,干脆把竞争对手直接抓过来后,直接建立一个库,然后返回数据给用户,这个真是比较机智。到后面都占据搜索市场10%以上。当然这里有个法律安全问题。
话说回来,讲到爬虫的第二个作用-数据统计及分析, 这个范围就更多更广了,举一个很简单的例子,想看看各大招聘网站各类职务信息和热门网站以及薪水,想抓取雪球高回报用户的行为,找出推荐股票等等,我们都可以使用爬虫技术,来给我们收集数据,辅助我们决策。
基础知识:
现在我们进入本文的重点, 掌握爬虫技术需要那些知识和学习阶段的建议。
1. 编程语言

首先入门,需要学习一门编程语言,以Python为例,基础语法、类、函数、数据结构中的list和dict等,跟着例子敲敲,网上资源很多,书籍像《笨办法学Python》, 网站像廖雪峰的个人网站,都是有不错的资源。
2. HTTP协议
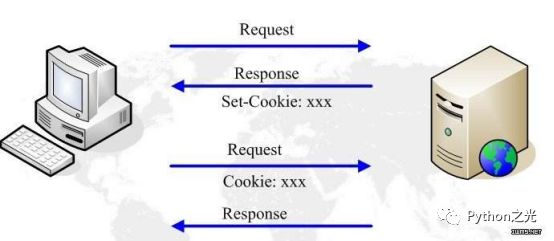
爬虫就是通过网络请求从远程服务器下载数据的过程,互联网消息传输的基本协议就是http协议,先了解基本的get,post,delete等方法和编码。慢慢地掌握浏览器是发送http请求向目标站点获取资源信息,熟悉格式规范。
网络请求框架都是对 HTTP 协议的实现,Python语言中著名的网络请求库 Requests就是一个模拟浏览器发送 HTTP 请求的网络库。相当于通过这个库打开的新世界的大门, 我们可以获取网页的源代码。了解 HTTP 协议之后,学有余力,就可以专门有针对性的学习和网络相关的模块了,Python 自带有 urllib、urllib2(Python3中的urllib),httplib,Cookie等内容,也可以暂时先跳过。把Requests的API弄熟。
3. HTML语言

很基础的内容,我们要爬取网页,自然需要知道网页使用的技术,知道文档树概念,30分钟就大致了解即可。
4.数据格式(HTML文本, XML 或者Json格式)
我们通过网络请求库 Reuests 获得从网站服务器后端发过来数据,数据有可能有不同的格式正确处理这些数据,你要熟悉每种数据类型的解决方案,比如 JSON 数据可以直接使用 Python自带的模块 json等。
5.解析工具
我的的目标信息藏在网页里,那么通过什么方法可以提取呢?传统的方法是使用正则表达式(Python模块中的re),对于Python而言,我们有方便的第三方解析库,可以使用。像Pyquery,BeautifulSoup等,学习方法最快速的无非是看官方文档中的quickstart先熟悉API。推荐使用Pyquery,它模仿Jquery几乎同样的API接口,对DOM操作十分方便。
6. 数据库知识

爬取的数据需要持久化,数据库基本知识也需要掌握(MySQL、SQLServer、Oracle、Mongodb等)SQL语言(懂基本的增删改查:add、delete、update、select),时下非关系型数据库很流行,像Mongodb使用起来就简单便利。
7. 网络抓包/浏览器抓包

学会使用 Chrome 或者 FireFox 浏览器去审查元素,跟踪请求信息等等,现在大部分网站有配有APP和手机浏览器访问的地址,优先使用这些接口,相对更容易。还有 Fiddler 等代理工具的使用。
8. Ajax技术原理
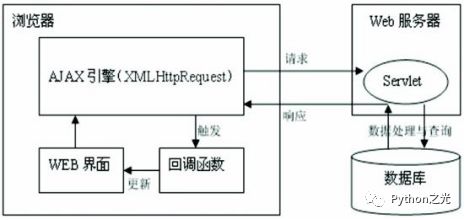
实际上就是浏览器提供了使用 HTTP 协议收发数据的接口,名为 AJAX,这像技术在web应用还比较广泛的,在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页的技术。
学习了以上,基本也清晰了整个爬取过程。一般地一个爬虫程序组成部分如首先Downloader负责下载页面(Requests、urllib),其次HTMLParser 负责解析页面(Pyquery lxml BeautifulSoup),最后是根据业务逻辑获取dataModel字段,完成资源采集。
限制:
当然作为被爬取的一方,我然有我不希望被被人爬取的内容,那限制爬取这些内容一般在robots.txt里。一个文明的爬虫,首先是看这个列表,哪些是敏感的不要爬。
以知乎为例#/robots.txt
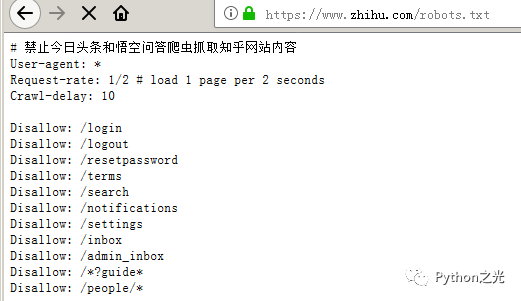
以上不允许爬取的内容就是相当于立了牌子,说禁止入内,robots.txt 只是约定,爬虫遵守或者不遵守完全在于爬虫作者的意愿。
第一次技术课程到此结束,我们总结一下,我们了解了爬虫的作用,可用做搜索和分析,其次探讨了爬虫技术的基本入门知识,编程语言,网络协议、数据库等知识,并对网站简单限制爬取做了简单阐述,后续有时间再更新···
本文内容转载自网络,本着传播与分享的原则,来源/作者信息已在文章顶部表明,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有




