Python培训
400-996-5531
400-996-5531
在用Linux的过程中也不是完全一无所获,还是做了点东西——用Python写了一个爬取58同城租房信息的小程序。然后再结合Excel来将其进行处理,效果奇好。这次由于涉及到的语言比较多,代码量较大,所以就不在此进行细讲,把注释好的代码贴出来,重点分享的是这个过程中的思路。希望大家对Excel处理数据有一个不同或者更深的认识。
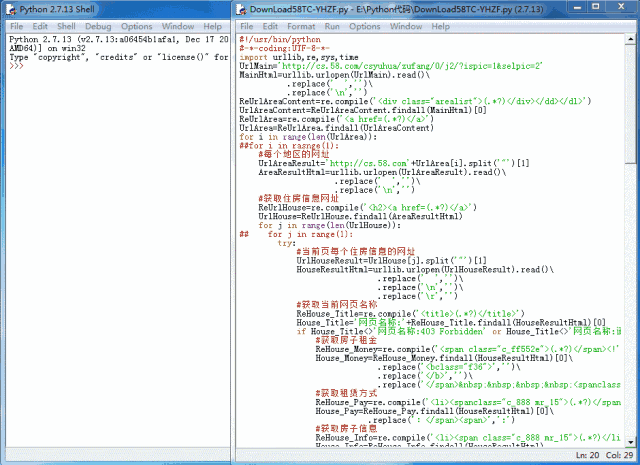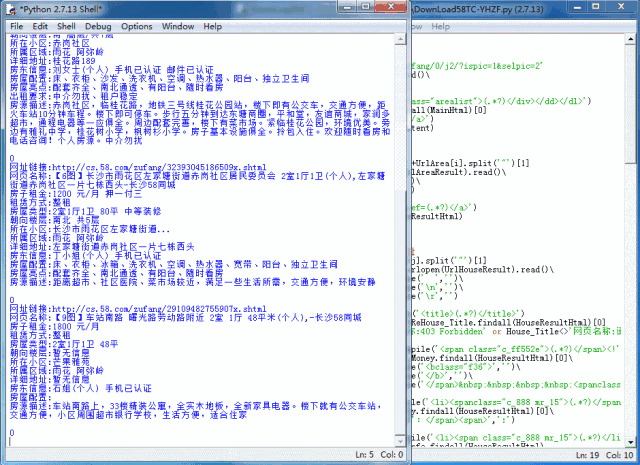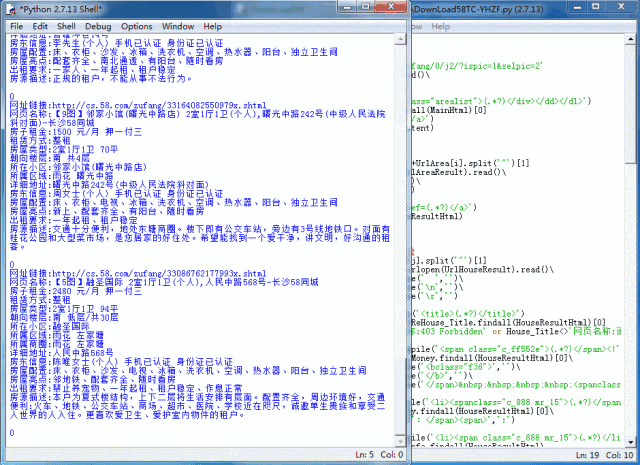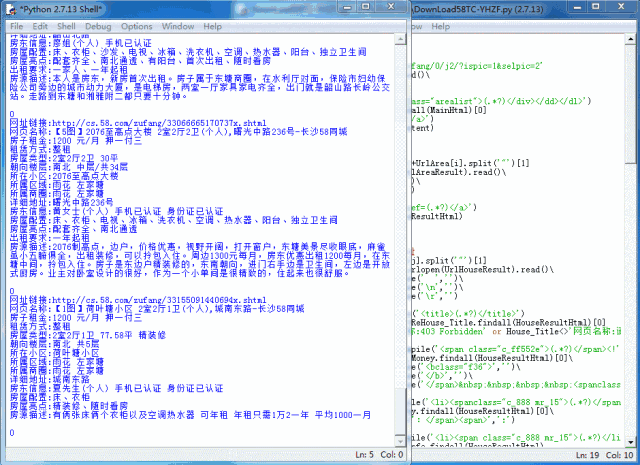
用Python提前写好程序,按下【F5】之后就可以批量爬取58同城上面的租房信息了。不过呢,虽然58上面的反爬虫机制似乎不太严,但是还是有一个【操作频繁】的监控,本来Yogurt是想通过控制访问时间来绕过这个监控的,后来发现不可行,可能是58是通过同一IP连续访问次数来判断这个【操作频繁】的,后来就索性不设置访问时间了,直接快速爬取。同时爬取速度与网络速度和网络稳定性有关,Yogurt在测试的时候,家里是4M的网络,用Wifi连接,家里还有其他用网设备,所以每隔一段时间就需要重新设置爬虫程序的爬取范围。
代码如下:
#!/usr/bin/python
#-*-coding:UTF-8-*-
import urllib,re,sys,time
UrlMain='http://cs.58.com/csyuhua/zufang/0/j2/?ispic=1&selpic=2'
MainHtml=urllib.urlopen(UrlMain).read()\
.replace(' ','')\
.replace('\n','')
ReUrlAreaContent=re.compile('<div class="arealist">(.*?)</div></dd></dl>')
UrlAreaContent=ReUrlAreaContent.findall(MainHtml)[0]
ReUrlArea=re.compile('<a href=(.*?)</a>')
UrlArea=ReUrlArea.findall(UrlAreaContent)
for i in range(len(UrlArea)):
#每个地区的网址#
UrlAreaResult='http://cs.58.com'+UrlArea[i].split('"')[1]
AreaResultHtml=urllib.urlopen(UrlAreaResult).read()\
.replace(' ','')\
.replace('\n','')
#获取住房信息网址#
ReUrlHouse=re.compile('<h2><a href=(.*?)</a>')
UrlHouse=ReUrlHouse.findall(AreaResultHtml)
for j in range(len(UrlHouse)):
try:
#当前页每个住房信息的网址
UrlHouseResult=UrlHouse[j].split('"')[1]
HouseResultHtml=urllib.urlopen(UrlHouseResult).read()\
.replace(' ','')\
.replace('\n','')\
.replace('\r','')
#获取当前网页名称
ReHouse_Title=re.compile('<title>(.*?)</title>')
House_Title='网页名称:'+ReHouse_Title.findall(HouseResultHtml)[0]
if House_Title<>'网页名称:403 Forbidden' or House_Title<>'网页名称:请输入验证码':
#获取房子租金
ReHouse_Money=re.compile('<span class="c_ff552e">(.*?)</span><!')
House_Money=ReHouse_Money.findall(HouseResultHtml)[0]\
.replace('<bclass="f36">','')\
.replace('</b>','')\
.replace('</span> <spanclass="c_333">',' ')
#获取租赁方式
ReHouse_Pay=re.compile('<li><spanclass="c_888 mr_15">(.*?)</span></li>')
House_Pay=ReHouse_Pay.findall(HouseResultHtml)[0]\
.replace(':</span><span>',':')
#获取房子信息
ReHouse_Info=re.compile('<li><span class="c_888 mr_15">(.*?)</li>')
House_Info=ReHouse_Info.findall(HouseResultHtml)
House_Infos=''
for k in range(len(House_Info)):
House_text=House_Info[k]\
.replace(':</span><span>',':')\
.replace(' ',' ')\
.replace(' </span>','')\
.replace('</span>','')
if k==2:
House_Infos+=House_text.split('<')[0]\
+House_text.split('>')[1].replace('</a','')+'\n'
elif k==3:
House_Infos+=House_text.split('<')[0]\
+House_text.split('>')[1].replace('</a',' ')\
+House_text.replace('</a>','').split('>')[2].replace('<emclass="dt c_888 f12"','')+'\n'
elif k==4:
House_Infos+=House_text.split('<')[0]\
+House_text.split('>')[1].replace('</a',' ')\
+House_text.replace('</a>','').split('>')[2]+'\n'
else:
House_Infos+=House_text+'\n'
#获取房子详细地址
ReHouse_Address=re.compile('<spanclass="c_888 mr_15">(.*?)</span></li>')
House_text=ReHouse_Address.findall(HouseResultHtml)[1]\
.replace(':</span>',':')
House_Address=House_text.split('<')[0]\
+House_text.split('>')[1].replace('</span','')
#获取房东信息
ReHouse_People=re.compile('<p class="agent-name f16 pr">(.*?)</i></p>')
House_text=ReHouse_People.findall(HouseResultHtml)[0].split('>')
for k in range(len(House_text)):
House_People=House_text[1].replace('</a','')\
+House_text[2]
if k>5:
House_People=House_People+House_text[4]+House_text[6]
elif k>3:
House_People=House_People+House_text[4]
else:
House_People=House_People
House_People='房东信息:'+House_People\
.replace('<i class="icon pho-approve" title="',' ')\
.replace('"<i class="icon mail-approve" title="',' ')\
.replace('"<i class="icon single-approve" title="',' ')\
.replace('"','')
#获取房屋配置
ReHouse_Disposal=re.compile('<ul class="house(.*?)</ul>')
House_Disposal=ReHouse_Disposal.findall(HouseResultHtml)[0]
ReHouse_Allocation=re.compile('<li class="(.*?)</li>')
House_Allocation=ReHouse_Allocation.findall(House_Disposal)
House_text=''
if len(House_Allocation)>1:
for k in range(len(House_Allocation)):
House_text+='、'+House_Allocation[k].split('</i>')[1]
House_Allocation='房屋配置:'+House_text.replace('、','',1)
else:
House_Allocation='房屋配置:'
#获取房屋其他信息
ReHouse_Item=re.compile("<ul class='introduce-item'>(.*?)</ul>")
House_Item=ReHouse_Item.findall(HouseResultHtml)[0]
ReHouse_OtherInfo=re.compile("<li><span class='a1'>(.*?)</span></li>")
House_OtherInfo=ReHouse_OtherInfo.findall(HouseResultHtml)
House_text=''
for k in range(len(House_OtherInfo)):
House_text+=House_OtherInfo[k]+'\n'
House_OtherInfo=House_text\
.replace("</span><span class='a2'>",':')\
.replace('</em><em>','、')\
.replace('<em>','')\
.replace('</em>','')\
.replace('<p>','')\
.replace('<p >','')\
.replace('</p>','')\
.replace('<b>','')\
.replace('</b>','')\
.replace('<br>','')\
.replace('<br >','')\
.replace('<br />','')\
.replace(' ','')\
.replace('<span >','')\
.replace('<span>','')\
.replace('</span>','')\
.replace('<strong>','')\
.replace('<strong >','')\
.replace('</strong>','')
House_InfoText='网址链接:'+UrlHouseResult+'\n'\
+House_Title+'\n'\
+'房子租金:'+House_Money+'\n'\
+House_Pay+'\n'\
+House_Infos\
+House_Address+'\n'\
+House_People+'\n'\
+House_Allocation+'\n'\
+House_OtherInfo
FileName=UrlArea[i].split('"')[4].replace('>','').decode('utf8').encode('gb2312')+'.txt'
FileSave=open(sys.path[0]+'/'+FileName,'a')
FileContent=House_InfoText+'\n'
FileSave.write(FileContent.decode('utf8').encode('gb2312'))
FileSave.close
print House_InfoText+'\n'+str(i)
else:
print '\n'
except:
print '检查网络情况'
time.sleep(10)
next
上面的爬取效果是特地保留下来的,其目的是为了确认代码的运行,在运行过程中将其内容保存到txt文件中进行保存。以便下一步的处理。
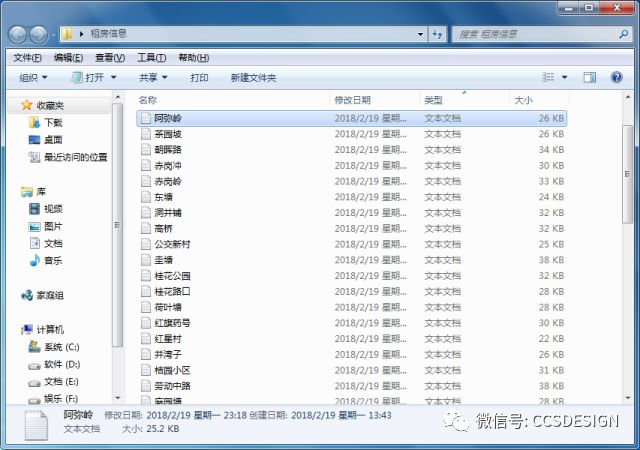
由于直接使用Python生成Excel需要第三方库的支持,而Yogurt比较懒,不想去找这些库,所以就用txt文件为连接Python和Excel的媒介。
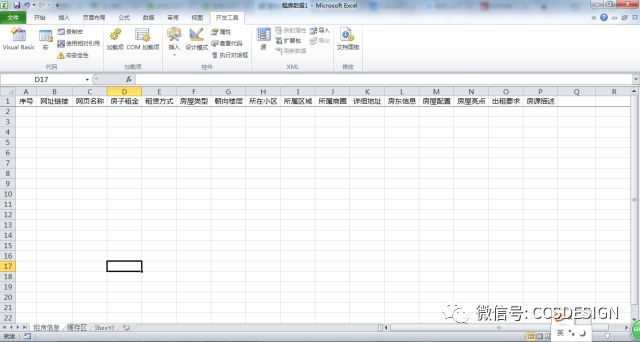
首先我们需要建立一个【Excel启用宏的工作簿】,建立两张表——一个【租房信息】,用于存放处理结果,一个【缓存区】用于记录和处理导入的每一个txt文件。
然后,通过VBA结合数组函数将导入的txt文件进行处理
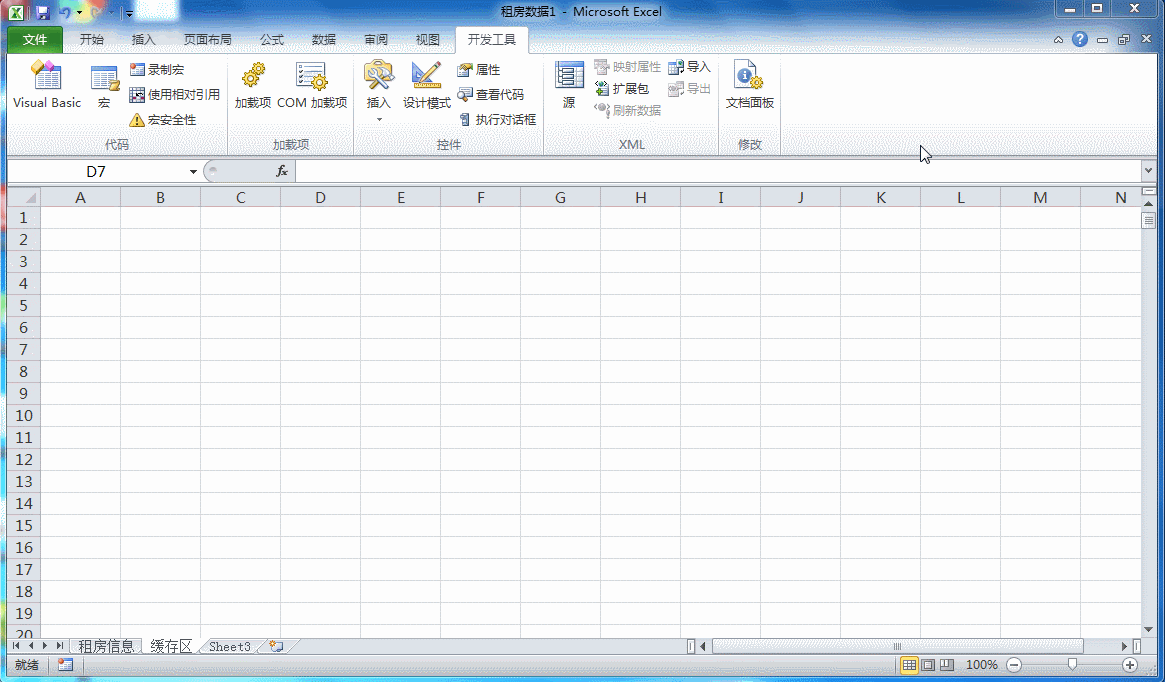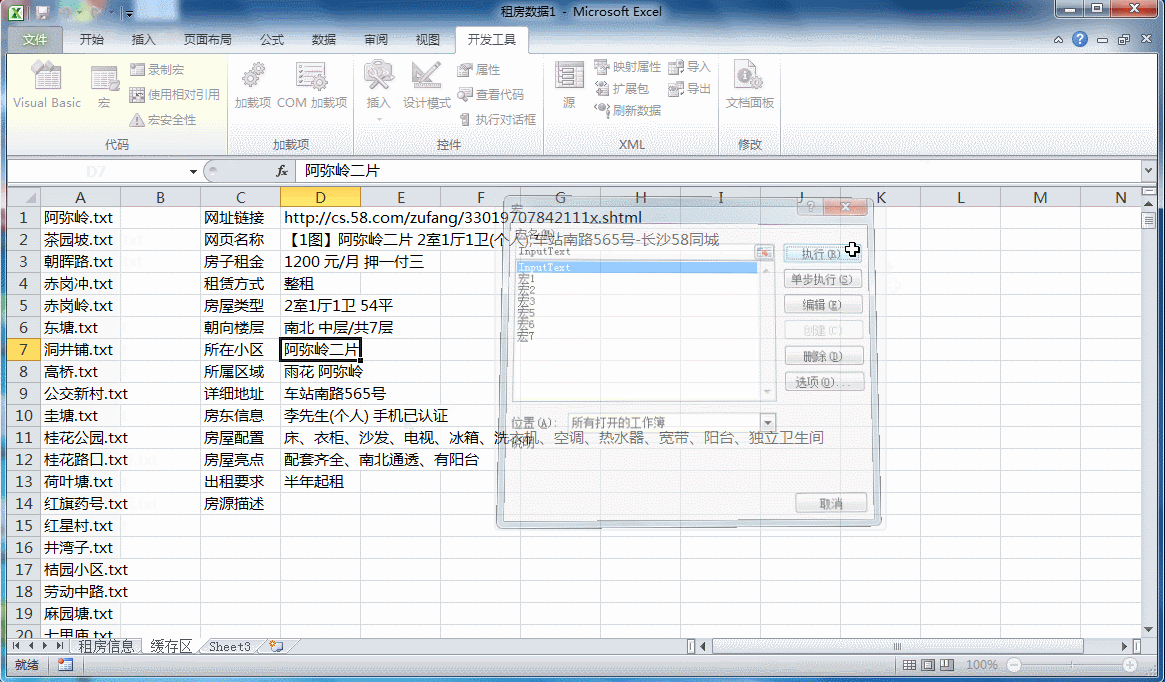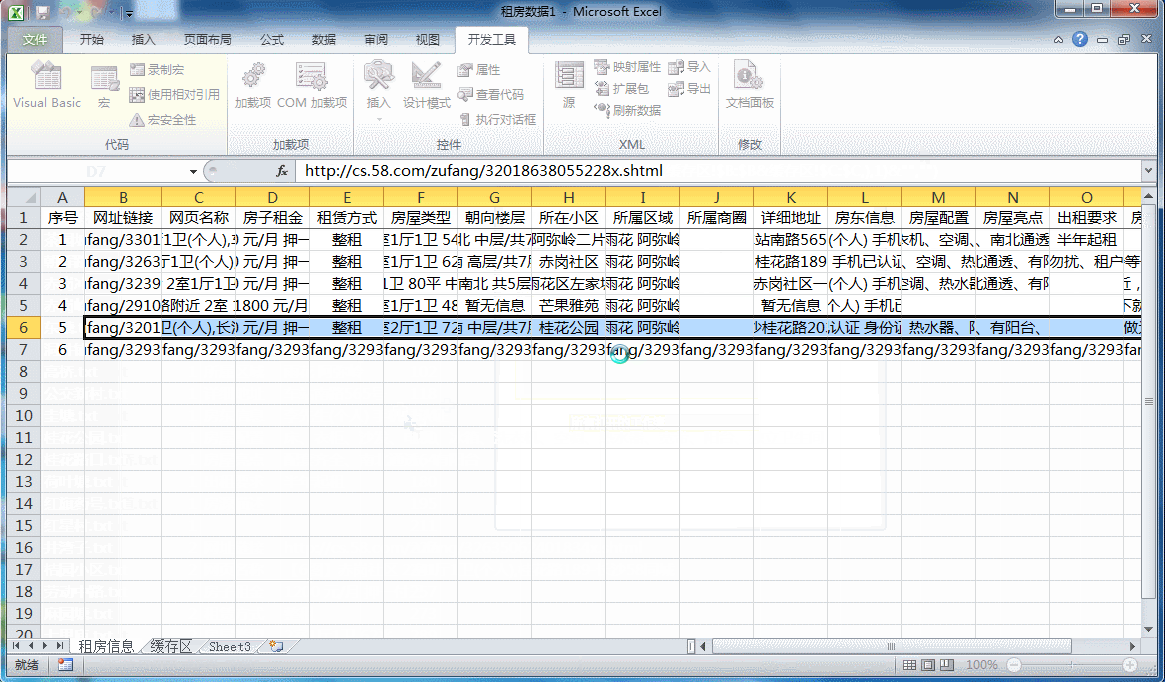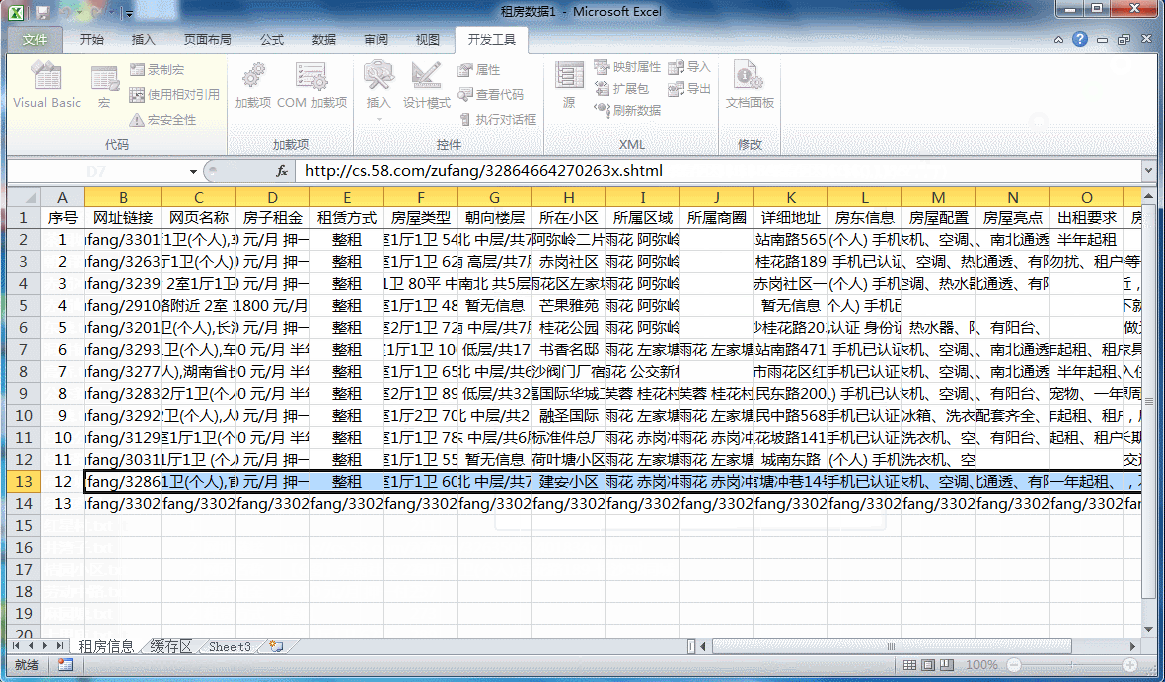
这里Yogurt图方便,用VBA代码直接在单元格中插入数组函数:
{=IFERROR(INDEX(缓存区!$D:$D,MATCH($A2&B$1,缓存区!$B:$B&缓存区!$C:$C,),1)&"","")}
数据庞大,Yogurt在前一天晚上把代码写好,测试通过之后就打开电脑让它自己执行了一夜,第二天早上起来验收。
代码如下:
Sub InputText()
On Error Resume Next
Dim FileAddress As String
Dim FileNames As String
Dim Rank As Integer
FileAddress = ThisWorkbook.Path & "\*.txt" 'txt文件地址
FileNames = Dir(FileAddress, vbNormal) '获取txt文件名称
Rank = 1 '使获取txt文件名称的起始顺序为1
Sheet1.Range("A2:P60000").ClearContents '清空【租房信息】中的数据内容
With ThisWorkbook.Sheets(2)
.Range("A:A").ClearContents '清空存放txt文件名称的单元格
Do While FileNames <> "" '设置循环获取,直至找不到txt文件名为止
.Range("A" & Rank) = FileNames '当存在txt文件名时将其输入到【缓存区】A列单元格中
FileNames = Dir '获取下一个内容
Rank = Rank + 1 '单元格位置向下移动1位
Loop
Dim RangeCount As Integer
RangeCount = .Range("A10000").End(xlUp).Row '获取导入txt文件名称的总数量
With .Sort 'A列单元格内容按照拼音顺序进行排序
.SortFields.Clear
.SortFields.Add Key:=Range("A1"), SortOn:=xlSortOnValues, Order:=xlAscending, DataOption:=xlSortNormal
.SetRange Range("A1:A" & RangeCount)
.Header = xlNo
.MatchCase = False
.Orientation = xlTopToBottom
.SortMethod = xlPinYin
.Apply
End With
Dim myText As String
Dim myArr() As String
Dim RangeCountText As Integer
Dim RangeEndRow As Integer
Dim StartNum As Integer
Dim EndNum As Integer
For i = 1 To RangeCount
.Range("B:D").ClearContents '在导入新的txt文件内容前清除缓存区中存放txt文件内容的单元格
Open ThisWorkbook.Path & "\" & .Range("A" & i) For Input As #1 '打开指定的txt文件
j = 1
Do While Not EOF(1) '从第一行到最后一样获取txt内容,并将其填充到C、D两列中
Line Input #1, myText
.Range("C" & j) = Left(myText, 4)
.Range("D" & j) = Mid(myText, 6)
j = j + 1
Loop
Close #1 '关闭txt文件
RangeCountText = .Range("C10000").End(xlUp).Row '获取导入txt文件的行数
.Range("E:E").ClearContents '清空E列内容
.Range("E1") = 0 '使E1单元格的值为0
k = 2
For j = 1 To RangeCountText '从C1到C列有内容的单元格的最后一行
If .Range("C" & j) = "" Then '当C列中的单元格内容为空时
.Range("E" & k) = .Range("C" & j).Row '在E列填充该空单元格所在的行数
k = k + 1
End If
Next
RangeEndRow = .Range("E10000").End(xlUp).Row + 1 '在获取完所有空单元格的行数之后,将C列中最后一个空单元格的位置赋值给RangeEndRow
.Range("E" & RangeEndRow) = RangeCountText '并使该单元格所在行数填入E列最后一位单元格中
k = 1
For j = 1 To RangeEndRow '从E1到E列有内容的单元格的最后一行
StartNum = .Range("E" & j) '将E列上下相邻的两位数的第一位赋值给StartNum
EndNum = .Range("E" & j + 1) '第二位赋值给EndNum
If j = RangeEndRow Then Exit For '如果循环到最后一行则停止循环
.Range("B" & StartNum + 1 & ":B" & EndNum) = k '将C列txt内容中相同信息的填上相同的序号
k = k + 1
Next
For j = 1 To k - 1
With Sheet1
RangeEndRow_1 = .Range("A60000").End(xlUp).Row '循环获取【租房信息】中A列不为空单元格的行数
.Range("A" & RangeEndRow_1 + 1) = j '使A列顺序填充序号
With .Range("B" & RangeEndRow_1 + 1) '在当前序号行中填充数组函数
.FormulaArray = "=IFERROR(INDEX(缓存区!C4,MATCH(RC1&R1C,缓存区!C2&缓存区!C3,),1)&"""","""")"
.AutoFill Sheet1.Range("B" & RangeEndRow_1 + 1 & ":P" & RangeEndRow_1 + 1), xlFillDefault
With Sheet1.Range("B" & RangeEndRow_1 + 1 & ":P" & RangeEndRow_1 + 1) '复制当前序号行内容,并使其内容格式填充为数值
.Copy
.PasteSpecial Paste:=xlPasteValues, Operation:=xlNone, SkipBlanks:=False, Transpose:=False
End With
End With
End With
Next
Next
End With
End Sub
3.1 地区排序
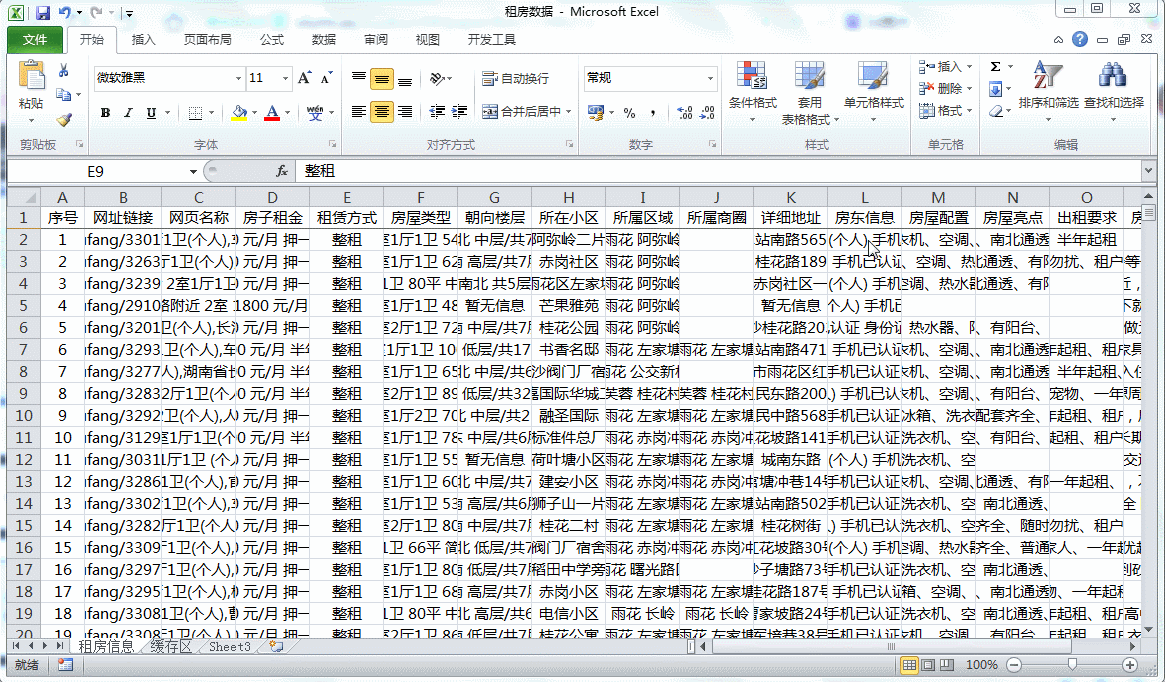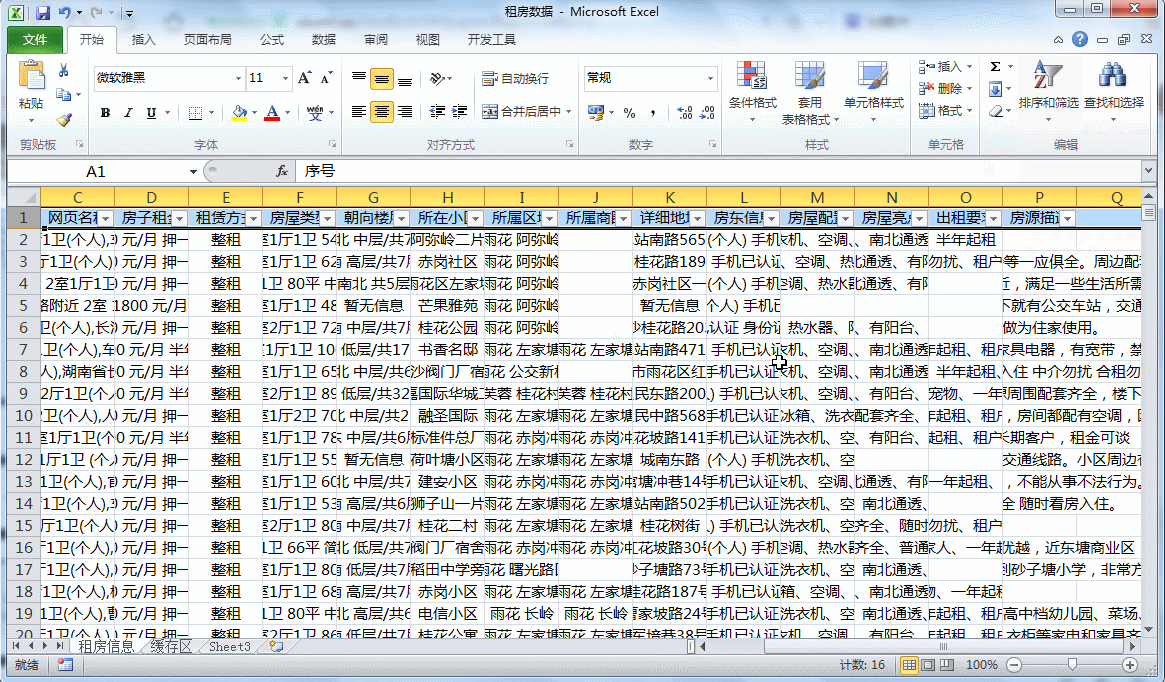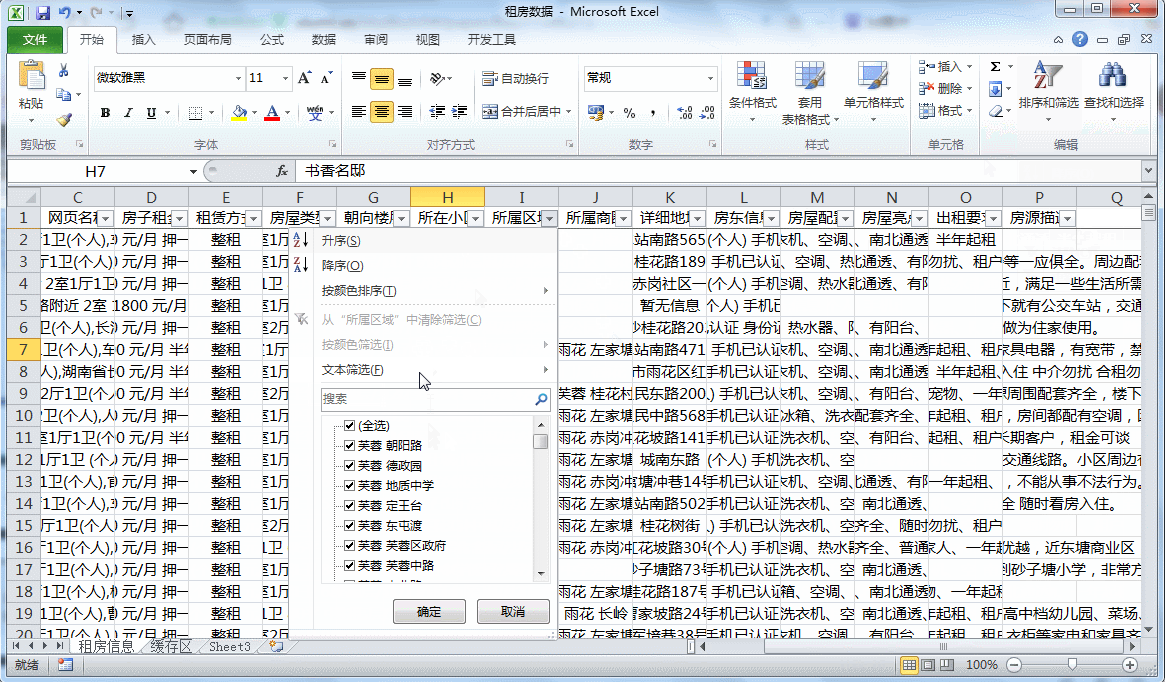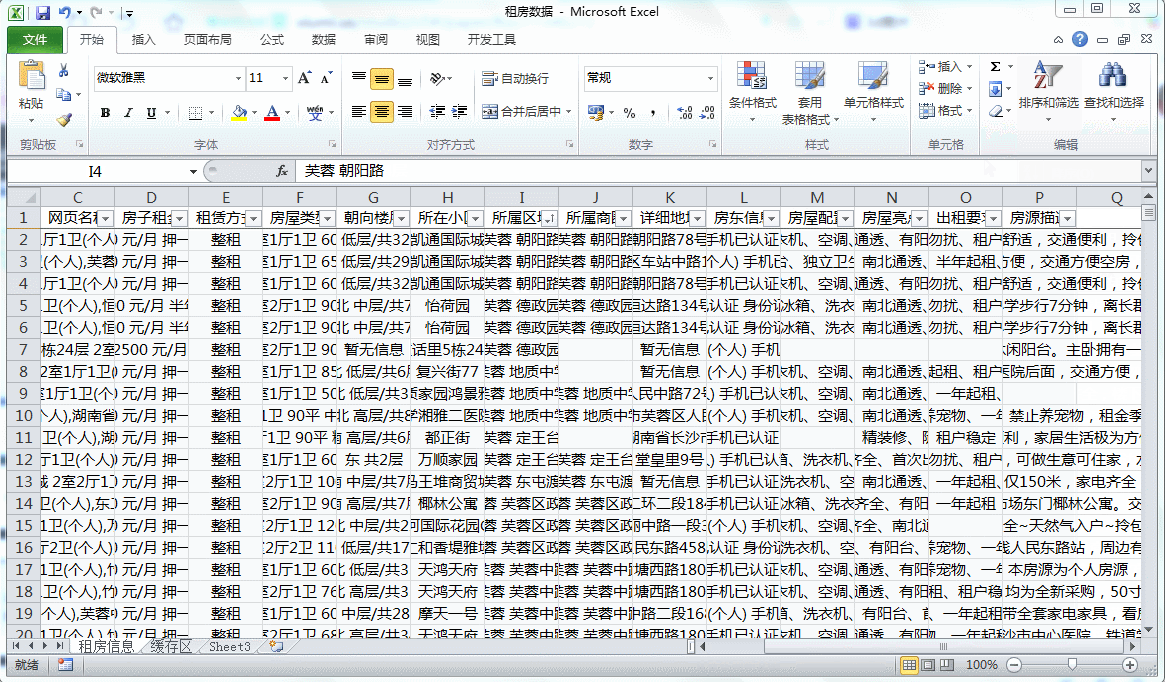
将地区进行排序之后,咱们需要重新将序号进行填充。因为上面的代码是按照【数字+标题名】的形式对导入的txt文件内容进行查找的,每一个txt文件中都是重新排序的,因此不符合我们汇总的要求,所以我们此时需要对其进行重新安排。
3.2 重新设定序号
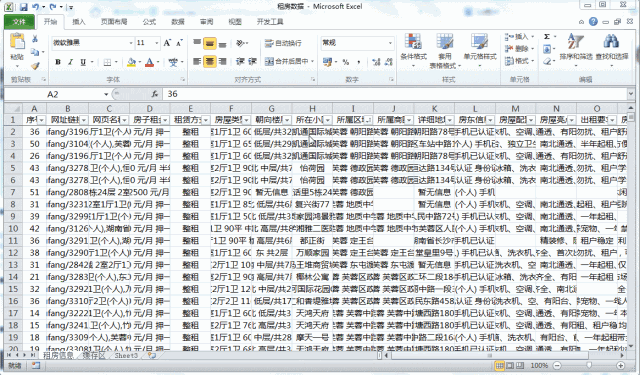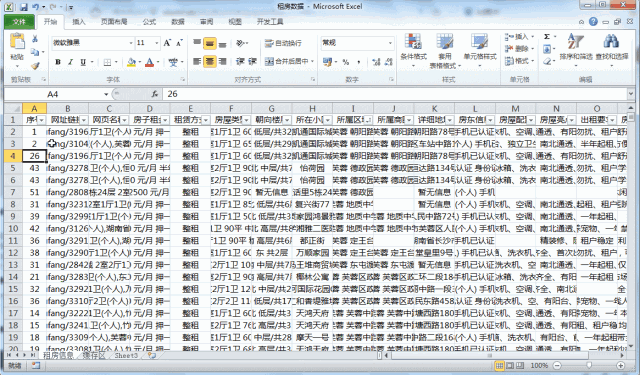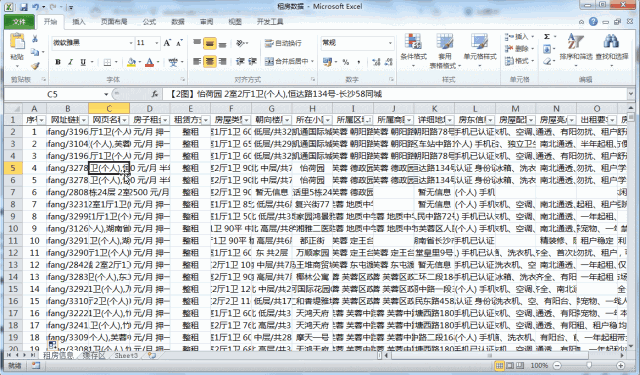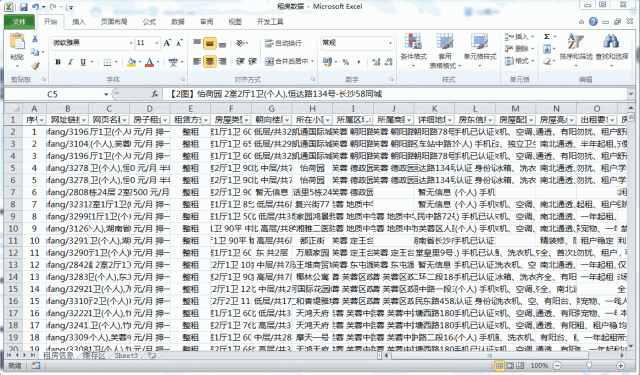
在序号列中的开头两位中输入起始值和特定步长后的值,选中两个单元格后双击右下角的小黑点即可完成所有行序号的填充。
3.3 细化列表条件

我们看到,按照从58上爬下来的数据,很多都连在了一起,比如【房子租金】列中【房租】和【支付方式】连在了一起;【朝向楼层】中房子的【朝向】和【楼层】连在了一起;【所属区域】中,【行政区域】和【地名】连在了一起等等……这样的数据对我们后期的统计和分析会产生不好的影响,因此我们需要尽可能的将列表的分列条件进行细化,以便于后期的处理和分析。
在此之前,我们需要考虑到原始数据的获取和生成都是需要耗费大量的时间和精力的,因此,为了后期处理过程中避免操作失误导致数据丢失,我们需要新建一张表来调用此表中的数据。
经过近1个小时的处理,形成了下面的这么一张长图:
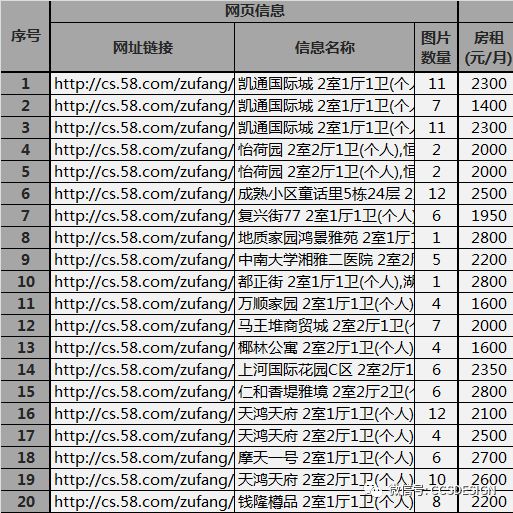
具体的函数使用大家可以通过在公众号的对话框中回复【爬虫】获取源文件。特地标出来的灰色隐藏信息列,是直接从【租房信息】表中直接用函数提取出来的内容。在我们查看的过程中是不需要出现的。
在进行简单的处理之后,让表格更加易于查看。如下图:
这样处理完后表才有益于后期的分析和处理,以便数据的展示等等。
以上就是Excel+Python获取58租房信息后的数据处理和汇总的全过程和代码内容。不知道对大家有没有一点点小启发。
在本期的最后呢,Yogurt想再多说点题外话。在一般的情况下,很多小伙伴都只知道Excel可以输入各种表格信息。很少会去思考Excel可以做一些更深层次的东西。新的一年,Yogurt用Excel+Python给大家分享了一个Excel对于处理来自网络的数据思路。希望能给大家一点在Excel上能够挖掘出更多好玩的操作方式。
这里顺便分享一下Python这个软件吧。
Python(/ˈpaɪθən/),是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。
简单地说,Python是一种相对于其他编程语言来说比较容易入门的一种语言,而且可以在短时间内学会并开发出相对不错的小作品。在云计算、大数据方面的应用颇多,在互联网技术、人3工智能等等方面中的表现优异。目前有2.x和3.x版两种版本。Yogurt目前使用的是Python 2.7.13 for Windows 64bit。
本文内容转载自网络,本着传播与分享的原则,来源/作者信息已在文章顶部表明,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有