

Python培训
400-996-5531
400-996-5531
文章简介
经常刷微博的同学肯定会关注一些有比较意思的博主,看看他们发的文字、图片、视频和底下评论,但时间一长,可能因为各种各样的原因,等你想去翻看某个博主的某条微博时,发现它已经被删除了,更夸张的是发现该博主已经被封号。那么如果你有很感兴趣的博主,不妨定期将Ta的微博保存,这样即使明天微博服务器全炸了,你也不用担心找不到那些微博了。(自己的微博也同理哦。)
看网上一些微博爬虫,都是针对很早之前的微博版本,而且爬取内容不全面,比如长微博不能完整爬取、图片没有爬取或没有分类,已经不适用于对当下版本微博内容的完整爬取了。
本例主要基于Python3.6.2版本,能够实现对于单博主微博内容的完整爬取、编号整理和本地保存。
环境介绍
Python3.6.2/Windows-7-64位/微博移动端
实现目标
将微博上你感兴趣的博主微博(全部或过滤非原创等)内容获取,包括微博文本、图片和热评,文本和热评按编号存入txt文件中,图片按编号存入指定路径文件夹中。这样一来方便对你关注的微博信息进行定期保存以及后期的检索查阅,二来将这些数据获取后也可以对博主微博、评论等信息进行进一步的数据分析。
本例中获取数据保存在本地文件系统,如爬取数据量大,可考虑使用MongoDB等数据库,方便数据存储和检索查阅。
准备工作
一般来说同一网站,PC站的信息较为全面,但不易爬取,而移动端则相对来说比较简单,因此本例中选取移动端站点#作为入口来进行爬取。
进入所要爬取的博主的主页,以我关注的“博物杂志”为例,发现其主页url为:#/u/1195054531?uid=1195054531&luicode=10000011&lfid=100103type%3D1%26q%3D%E5%8D%9A%E7%89%A9%E6%9D%82%E5%BF%97
其中1195054531这段数字就是我们要找的uid,然后打开在浏览器中输入url: #/u/1195054531 再次进入相同主页,这时候按F12打开谷歌开发者工具,点“Network”,因为移动端站点加载方式为异步加载,我们主要关注XHR下请求,点“XHR”,按F5刷新重新发送请求。这时候发现浏览器已经发送两个请求,第一个请求主要是为了获取一些和博主相关的介绍信息,而第二个请求就是为了获取第一页所有微博的信息,我们重点关注第二个请求。

点“Headers”,可以发现Request URL 、Cookie、Referer等我们需要的信息(Cookie信息这里采用手动获取方式,有效时间为几个小时不等,过期后需要手动重新获取一下), 其中Request URL为 #/api/container/getIndex?type=uid&value=1195054531&containerid=1076031195054531
后面通过观察发现,在这个url末尾加上&page=页数可以控制想要爬取的微博页数。 点“Preview”:
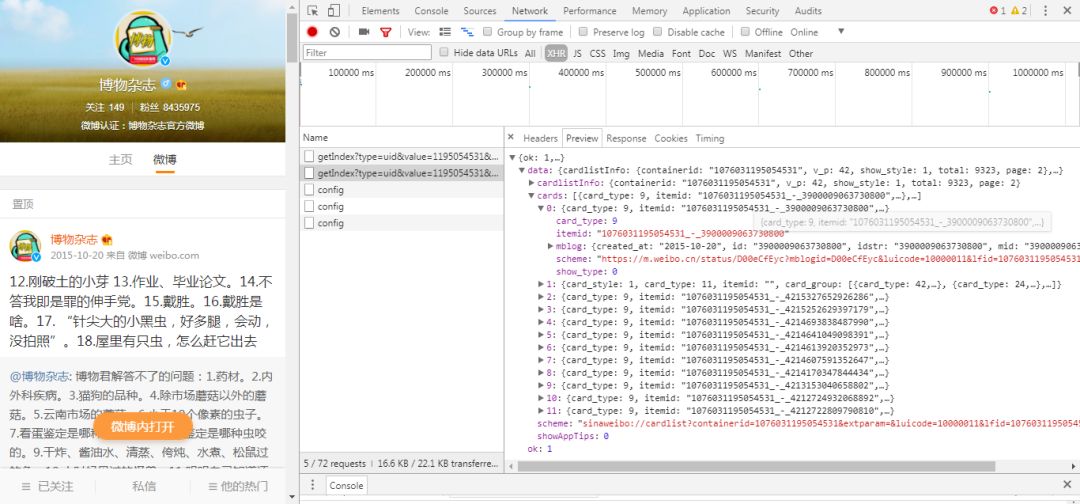
观察返回的json数据,cards下就是一条条微博的信息card。 点开mblog,可以获取详细的微博相关内容:
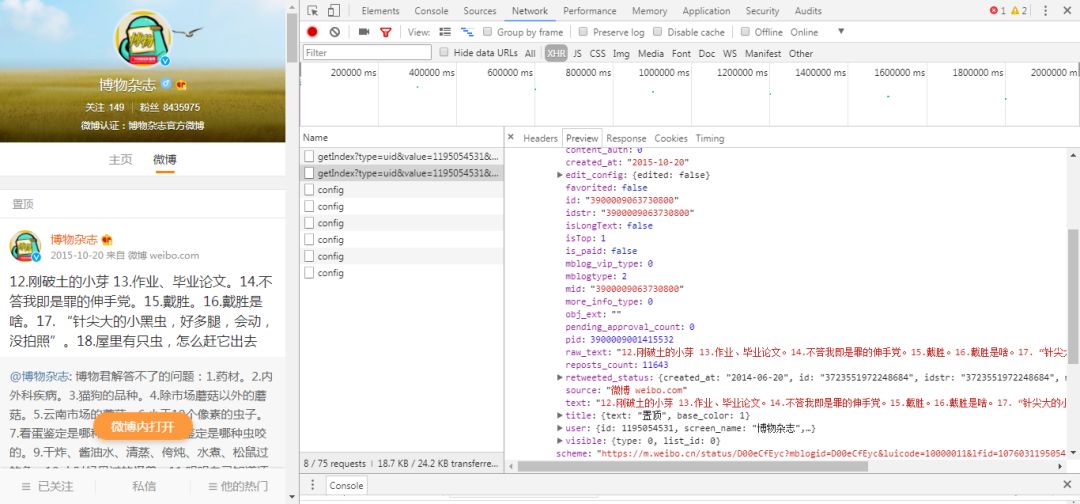
我们主要需要以下数据: ‘id’:微博编号 ‘text’:微博文本 ‘islongText’:判断该条微博是否为长微博 ‘bmiddle_pic’:判断该微博是否带有图片
点开某条具体微博,来到微博完整内容和评论页面,同理通过观察“Network中请求相关信息,可以发现该页面url为: #/api/comments/show?id=3900009063730800&page=1 其中id后面数字即为我们前面获取的微博编号,page参数可控制微博页数,请求返回json格式数据如下:
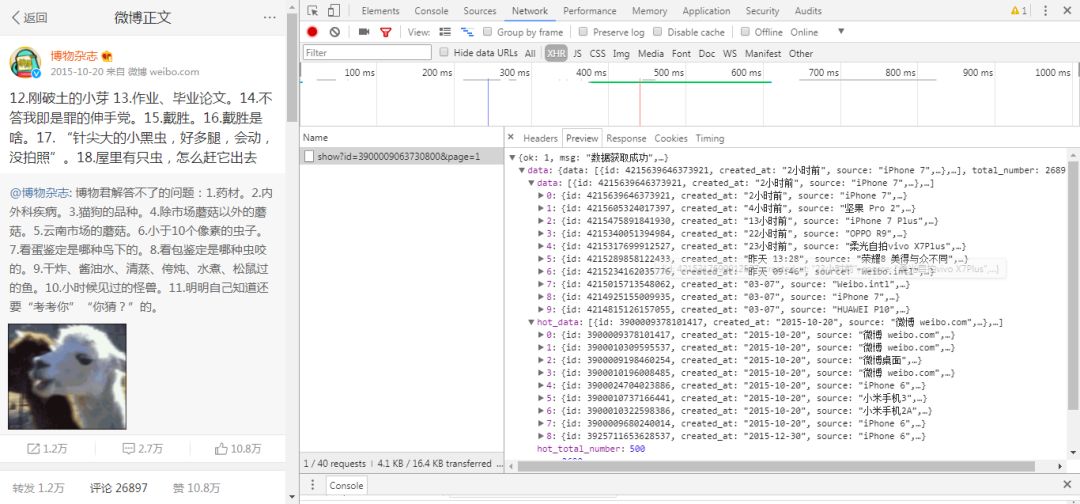
其中’data’和’hotdata’分别为评论和热评数据。
实现逻辑
通过控制page参数获取每页微博的cards数据,其中包含各条微博的详细信息;
开始遍历每一页微博页,同时遍历每一页的每一个微博,期间进行如下操作:
判断是否为长微博,如不是获取文本信息,否则进入详细微博内容请求,获取文本信息,将文本信息写入txt文档;
判断微博是否带有图片,如有通过请求获取图片地址,遍历地址,将其链接写入txt文档,将图片保存到本地,如无图片结束;
通过微博评论请求,获取评论数据列表,遍历列表获得该微博下每一条评论并保存到txt文档中相应微博内容下; …… 直到遍历完每一条微博。
爬取过程

爬取结果
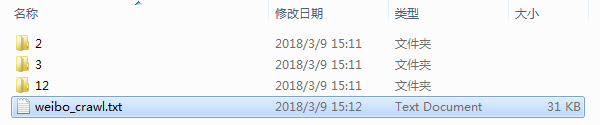
文件夹中为对应微博图片,txt文档中为爬取的微博文本、评论内容。
以爬取“博物杂志”第3条微博为例,原博内容如下:
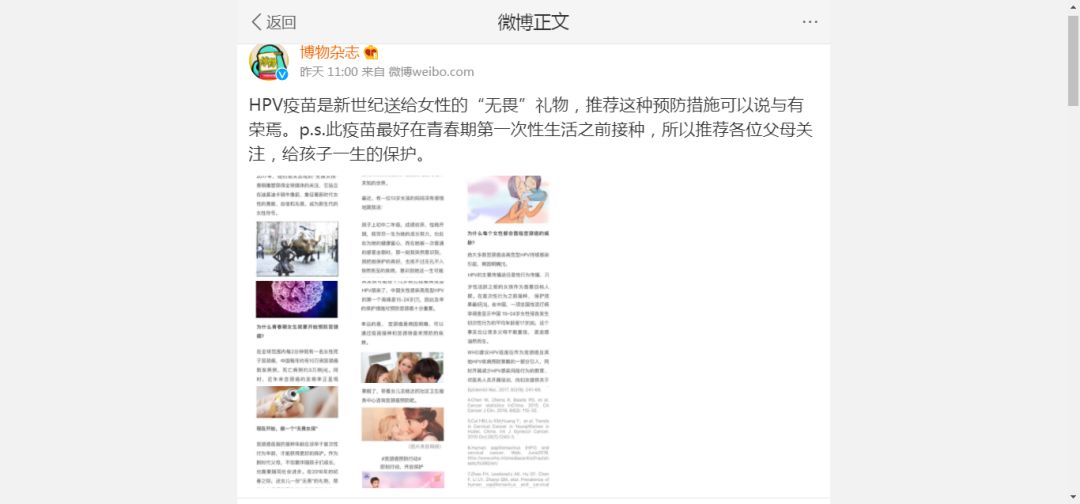
Txt文本中微博文本和评论如下:
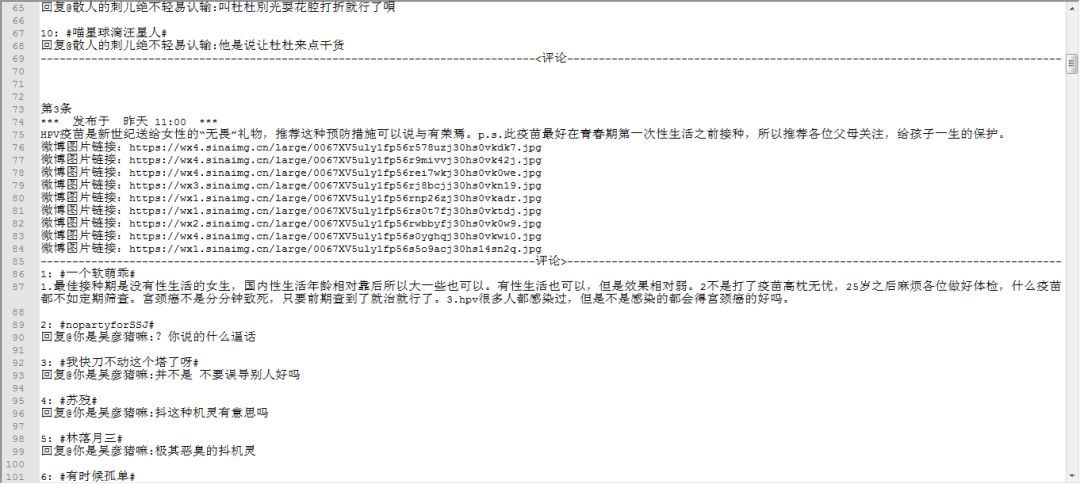
文件夹中对应图片如下:

相对来说可以比较方便地进行检索和查阅。
代码实现
# -*- coding:utf-8 -*-
'''
Created on 2018年3月9日
@author: ora_jason
'''
from lxmlimport html
import requests
import json
import re
import os
import time
import urllib.request
class CrawlWeibo:
# 获取指定博主的所有微博cards的list
defgetCards(self, id, page): # id(字符串类型):博主的用户id;page(整型):微博翻页参数
ii = 0
list_cards = []
while ii < page:
ii = ii + 1
print('正在爬取第%d页cards' % ii)
url = '#/api/container/getIndex?type=uid&value=' + id + '&containerid=107603' + id + '&page=' + str(
ii)
response = requests.get(url, headers=headers)
ob_json = json.loads(response.text) # ob_json为dict类型
list_cards.append(ob_json['data']['cards']) # ob_json['data']['cards']为list类型
time.sleep(2)
print('暂停2秒') # 爬完一页所有微博的cards后 停顿两秒
return list_cards# 返回所有页的cards
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有




