

Python培训
400-996-5531
400-996-5531
本文来自作者 刘明 在 GitChat 上分享 「Python 机器学习 Scikit-learn 完全入门指南」
编辑 | 伏特加

使用 Python 的科研人员,几乎都用过 SciPy。
SciPy 是一个开源的 Python 科学计算库,其中涵盖了科学计算中的各种工具,包括统计、积分、插值、最优化,图像处理等等。
SciPy 可以与 NumPy 合作,高效地进行矩阵计算。而各种不同领域的开发者们,在 SciPy 的基础上发展出许多分支版本,统一称为 Scikits,即 SciPy 工具箱。
而其中应用最广,也是机器学习领域最知名的分支版本,就是本文的主角 Scikit-learn。
Scikit-learn 是基于 Numpy 与 SciPy 两大著名工具包,通常与 pandas、Matplotlib 等开源数据处理框架合作,进行数据挖掘任务。
本文将介绍安装和运行 Scikit-learn 的大体步骤,而后重点讲解 Scikit-learn 框架的几大功能。本文的操作理论上在 Python 3.x 版本下通用,但目前建议在 Python 3.6 版本下使用。
由于本文面向的对象为初学者,大多使用 Windows 系统,所以本文的所有操作,建立在为 64 位的 Windows 10 系统上。
此步仅为了文章对 Python 小白友好,老鸟请大胆跳过此步,直接开始学习下面的内容。
由于 Scikit-learn 是基于 Numpy 与 Scipy 等包的支持,所以需要在安装 Scikit-learn 之前安装这些工具包,由于安装这些工具包的过程繁琐,个人建议使用环境管理工具进行安装。
本文的安装是基于 Anaconda 进行的,下载时请注意选择 Python 3.6 版本。由于安装过程极其简单,这里就不再赘述。
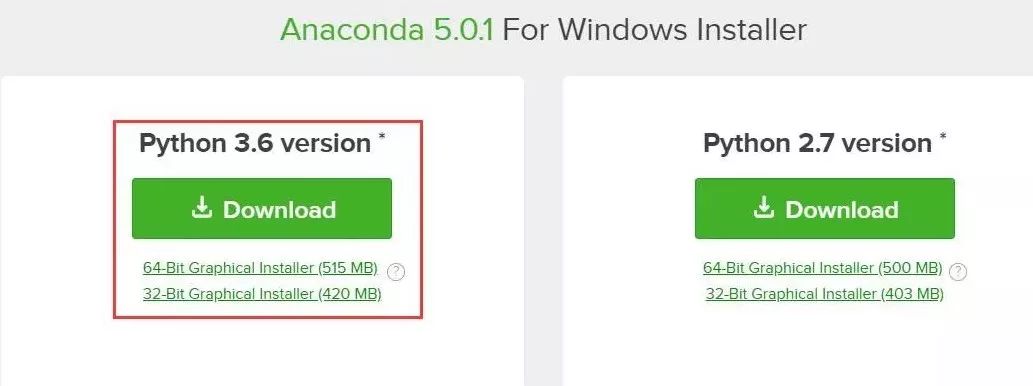
安装好 Anaconda 后,可以使用 pip 命令直接安装 Scikit-learn,命令如下:
pip install scikit-learn
在 Linux 下,可使用以下命令:
$ sudo pip install -U scikit-learn
前面写上 sudo 是为了防止安装过程中遇到权限问题,如果已取得管理员权限可以省略。
导入 Scikit-learn 也很简单,Scikit-learn 的简写为 sklearn,所以在 Python 中导入 Scikit-learn 的语法为:
import sklearn
当然,通常的使用以下方法。
from sklearn import xxx
简单无脑吧!我都觉得讲解安装有点多此一举。
想要使用机器学习进行数据挖掘,首先要导入数据,而最常用的数据集管理包就是 pandas:#。
本文的重点为 Scikit-learn,所以这里不过多讲解 pandas 的内容。
假设,这里有一个 Data.csv 数据集,内容如下图,10 行数据,包括 3 个特征:国家、年龄、薪水,预测的目标为:是否购买了该产品。
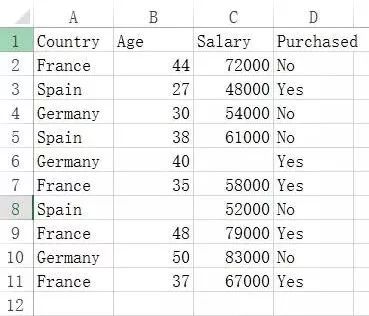
先导入数据集,并将特征与目标分别存入 X 与 y 中,命令如下:
import pandas as pd dataset = pd.read_csv('Data.csv') X = dataset.iloc[:,:-1].values y = dataset.iloc[:,3].values
这时,X 的值为:
array([['France', 44.0, 72000.0], ['Spain', 27.0, 48000.0], ['Germany', 30.0, 54000.0], ['Spain', 38.0, 61000.0], ['Germany', 40.0, nan], ['France', 35.0, 58000.0], ['Spain', nan, 52000.0], ['France', 48.0, 79000.0], ['Germany', 50.0, 83000.0], ['France', 37.0, 67000.0]])
y 的值为:
array(['No', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes'])
可以看出,Age 与 Salary 中都有缺失值。补全缺失值,可以使用 Scikit-learn 库的预处理工具 Imputer。
sklearn.preprocessing.Imputer,将缺失值替换为均值、中位数、众数,下面的例子使用均值作为替换。
from sklearn.preprocessing import Imputer imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0) imputer.fit(X[:, 1:3]) X[:, 1:3] = imputer.transform(X[:, 1:3])
下面,来具体解析这段代码的含义。
第 1 行,导入 Imputer,其中 Imputer 是一个对象(class)。
第 2 行,实例化 Imputer 类,并命名为 imputer。Imputer 在实例化时,可以传入如下几个值:
missing_values:缺失值,默认为 NaN,可以为整数或者 NaN(缺失值 numpy.nan 用字符串 NaN 表示)。
strategy:替换策略,字符串,默认用均值 mean 替换。
①若为 mean,用特征列的均值替换;
②若为 median,用特征列的中位数替换;
③若为 most_frequent ,用特征列的众数替换。
axis:指定轴号,如果是二维数据,默认 axis=0 代表列,axis=1 代表行。
第 3 行,imputer 实例使用 fit 方法,对特征集 X 进行分析拟合。拟合后,imputer 会产生一个 statistics_ 参数,其值为 X 每列的均值、中位数、众数。
第 4 行,使用 imputer 的 transform 方法填充 X 的值,并重新赋值给 X。
sklearn 大多数据预处理工具的使用方法,都与此相同,主要有以下几点。
1)导入
from sklearn.preprocessing import Xxx
2)创建实例
xxx = Xxx(a='xxx', b='yyy', c=.......)
3)对数据集进行分析拟合
xxx.fit(X_data)
4)对数据集进行变换
X_data = xxx.transform(X_data)
可以看出,顺序是:
导入库;
实例化;
fit;
transform。
除了 Imputer,接下来再拿其他的预处理工具举例子。
Binarizer:二值化工具,将数据分为 0 和 1,其只需要传入一个参数 threshold(阈值),其小于或等于该值的数据会变为 0,大于该值的数据会变为 1。
举一个小例子,如下:
>>> X_data = np.array([[0.3, 0.6], [0.7, 0.5]])#创建数据集>>> from sklearn.preprocessing import Binarizer#导入库>>> binarizer = Binarizer(threshold=0.5)#实例化>>> binarizer.fit(X_data)#fitBinarizer(copy=True, threshold=0.5)>>> X_data = binarizer.transform(X_data)#transform>>> X_data array([[ 0., 1.], [ 1., 0.]])
简单吧,与我们先前给出的步骤完全相同,即:
导入库;
实例化;
fit;
transform。
请记住这个顺(套)序(路)!
我们再看一个例子。
LabelEncoder:标签编码工具,将标签编码为数字,其顺序排列基于 ASCII 码。比如,将 “amsterdam”、“paris”、“tokyo” 分别标记为 0、1、2。
下面举一个官方给的例子。
>>> le = preprocessing.LabelEncoder()>>> le.fit(["paris", "paris", "tokyo", "amsterdam"]) LabelEncoder()>>> le.transform(["tokyo", "tokyo", "paris"]) array([2, 2, 1]...)>>> list(le.inverse_transform([2, 2, 1]))#反向变换['tokyo', 'tokyo', 'paris']
依旧是:
导入库;
实例化;
fit;
transform。
你记住了吗?
其余预处理工具,如 OneHotEncoder、MaxAbsScaler、PolynomialFeatures 等等,使用方法都与此相同,仅仅是传入的参数有差异。
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有




