

Python培训
400-996-5531
400-996-5531
你在阅读完“用Python 编写的 Python 解释器”时,你心中出现的符号是句号、问号还是叹号?带着你的所思所想,我们来阅读本文:Byterun是一个用Python实现的Python解释器,尽管Byterun很小,但它能执行大多数简单的Python程序。这个Python解释器的基础结构可以满足500行的限制。在这一章我们会搞清楚这个解释器的结构,给你足够的知识探索下去。
A Python Interpreter
在开始之前,让我们缩小一下“Pyhton解释器”的意思。在讨论Python的时候,“解释器”这个词可以用在很多不同的地方。有的时候解释器指的是REPL,当你在命令行下敲下python时所得到的交互式环境。有时候人们会相互替代的使用Python解释器和Python来说明执行Python代码的这一过程。在本章,“解释器”有一个更精确的意思:执行Python程序过程中的最后一步。
在解释器接手之前,Python会执行其他3个步骤:词法分析,语法解析和编译。这三步合起来把源代码转换成code object,它包含着解释器可以理解的指令。而解释器的工作就是解释code object中的指令。
你可能很奇怪执行Python代码会有编译这一步。Python通常被称为解释型语言,就像Ruby,Perl一样,它们和编译型语言相对,比如C,Rust。然而,这里的术语并不是它看起来的那样精确。大多数解释型语言包括Python,确实会有编译这一步。而Python被称为解释型的原因是相对于编译型语言,它在编译这一步的工作相对较少(解释器做相对多的工作)。在这章后面你会看到,Python的编译器比C语言编译器需要更少的关于程序行为的信息。
A Python Python Interpreter
Byterun是一个用Python写的Python解释器,这点可能让你感到奇怪,但没有比用C语言写C语言编译器更奇怪。(事实上,广泛使用的gcc编译器就是用C语言本身写的)你可以用几乎的任何语言写一个Python解释器。
用Python写Python既有优点又有缺点。最大的缺点就是速度:用Byterun执行代码要比用CPython执行慢的多,CPython解释器是用C语言实现的并做了优化。然而Byterun是为了学习而设计的,所以速度对我们不重要。使用Python最大优点是我们可以仅仅实现解释器,而不用担心Python运行时的部分,特别是对象系统。比如当Byterun需要创建一个类时,它就会回退到“真正”的Python。另外一个优势是Byterun很容易理解,部分原因是它是用高级语言写的(Python!)(另外我们不会对解释器做优化 — 再一次,清晰和简单比速度更重要)
Building an Interpreter
在我们考察Byterun代码之前,我们需要一些对解释器结构的高层次视角。Python解释器是如何工作的?
Python解释器是一个虚拟机,模拟真实计算机的软件。我们这个虚拟机是栈机器,它用几个栈来完成操作(与之相对的是寄存器机器,它从特定的内存地址读写数据)。
Python解释器是一个字节码解释器:它的输入是一些命令集合称作字节码。当你写Python代码时,词法分析器,语法解析器和编译器生成code object让解释器去操作。每个code object都包含一个要被执行的指令集合 — 它就是字节码 — 另外还有一些解释器需要的信息。字节码是Python代码的一个中间层表示:它以一种解释器可以理解的方式来表示源代码。这和汇编语言作为C语言和机器语言的中间表示很类似。
A Tiny Interpreter
为了让说明更具体,让我们从一个非常小的解释器开始。它只能计算两个数的和,只能理解三个指令。它执行的所有代码只是这三个指令的不同组合。下面就是这三个指令:
LOAD_VALUE
ADD_TWO_VALUES
PRINT_ANSWER
我们不关心词法,语法和编译,所以我们也不在乎这些指令是如何产生的。你可以想象,你写下7 + 5,然后一个编译器为你生成那三个指令的组合。如果你有一个合适的编译器,你甚至可以用Lisp的语法来写,只要它能生成相同的指令。
假设
7 + 5
生成这样的指令集:

Python解释器是一个栈机器,所以它必须通过操作栈来完成这个加法。(Figure 1.1)解释器先执行第一条指令,LOAD_VALUE,把第一个数压到栈中。接着它把第二个数也压到栈中。然后,第三条指令,ADD_TWO_VALUES,先把两个数从栈中弹出,加起来,再把结果压入栈中。最后一步,把结果弹出并输出。

LOAD_VALUE这条指令告诉解释器把一个数压入栈中,但指令本身并没有指明这个数是多少。指令需要一个额外的信息告诉解释器去哪里找到这个数。所以我们的指令集有两个部分:指令本身和一个常量列表。(在Python中,字节码就是我们称为的“指令”,而解释器执行的是code object。)
为什么不把数字直接嵌入指令之中?想象一下,如果我们加的不是数字,而是字符串。我们可不想把字符串这样的东西加到指令中,因为它可以有任意的长度。另外,我们这种设计也意味着我们只需要对象的一份拷贝,比如这个加法 7 + 7, 现在常量表 "numbers"只需包含一个7。
你可能会想为什么会需要除了ADD_TWO_VALUES之外的指令。的确,对于我们两个数加法,这个例子是有点人为制作的意思。然而,这个指令却是建造更复杂程序的轮子。比如,就我们目前定义的三个指令,只要给出正确的指令组合,我们可以做三个数的加法,或者任意个数的加法。同时,栈提供了一个清晰的方法去跟踪解释器的状态,这为我们增长的复杂性提供了支持。
现在让我们来完成我们的解释器。解释器对象需要一个栈,它可以用一个列表来表示。它还需要一个方法来描述怎样执行每条指令。比如,LOAD_VALUE会把一个值压入栈中。

这三个方法完成了解释器所理解的三条指令。但解释器还需要一样东西:一个能把所有东西结合在一起并执行的方法。这个方法就叫做run_code, 它把我们前面定义的字典结构what-to-execute作为参数,循环执行里面的每条指令,如何指令有参数,处理参数,然后调用解释器对象中相应的方法。
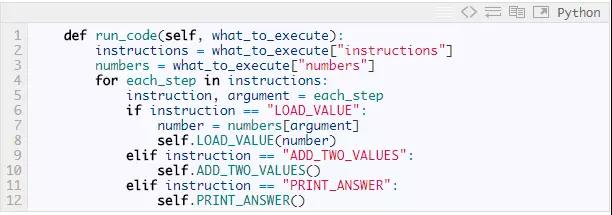
为了测试,我们创建一个解释器对象,然后用前面定义的 7 + 5 的指令集来调用run_code。

显然,它会输出12
尽管我们的解释器功能受限,但这个加法过程几乎和真正的Python解释器是一样的。这里,我们还有几点要注意。
首先,一些指令需要参数。在真正的Python bytecode中,大概有一半的指令有参数。像我们的例子一样,参数和指令打包在一起。注意指令的参数和传递给对应方法的参数是不同的。
第二,指令ADD_TWO_VALUES不需要任何参数,它从解释器栈中弹出所需的值。这正是以栈为基础的解释器的特点。
记得我们说过只要给出合适的指令集,不需要对解释器做任何改变,我们做多个数的加法。考虑下面的指令集,你觉得会发生什么?如果你有一个合适的编译器,什么代码才能编译出下面的指令集?

从这点出发,我们开始看到这种结构的可扩展性:我们可以通过向解释器对象增加方法来描述更多的操作(只要有一个编译器能为我们生成组织良好的指令集)。
Variables
接下来给我们的解释器增加变量的支持。我们需要一个保存变量值的指令,STORE_NAME;一个取变量值的指令LOAD_NAME;和一个变量到值的映射关系。目前,我们会忽略命名空间和作用域,所以我们可以把变量和值的映射直接存储在解释器对象中。最后,我们要保证what_to_execute除了一个常量列表,还要有个变量名字的列表。

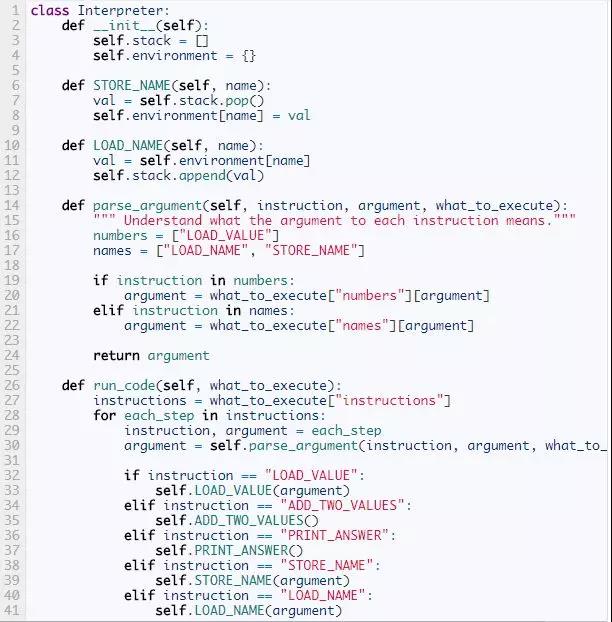
我们的新的的实现在下面。为了跟踪哪名字绑定到那个值,我们在__init__方法中增加一个environment字典。我们也增加了STORE_NAME和LOAD_NAME方法,它们获得变量名,然后从environment字典中设置或取出这个变量值。
现在指令参数就有两个不同的意思,它可能是numbers列表的索引,也可能是names列表的索引。解释器通过检查所执行的指令就能知道是那种参数。而我们打破这种逻辑 ,把指令和它所用何种参数的映射关系放在另一个单独的方法中。
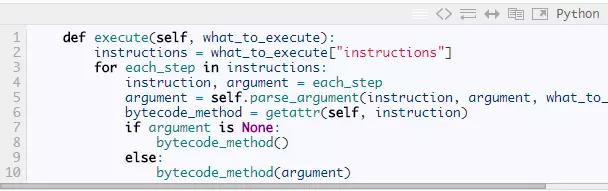
仅仅五个指令,run_code这个方法已经开始变得冗长了。如果保持这种结构,那么每条指令都需要一个if分支。这里,我们要利用Python的动态方法查找。我们总会给一个称为FOO的指令定义一个名为FOO的方法,这样我们就可用Python的getattr函数在运行时动态查找方法,而不用这个大大的分支结构。run_code方法现在是这样:
Real Python Bytecode
现在,放弃我们的小指令集,去看看真正的Python字节码。字节码的结构和我们的小解释器的指令集差不多,除了字节码用一个字节而不是一个名字来指示这条指令。为了理解它的结构,我们将考察一个函数的字节码。考虑下面这个例子:
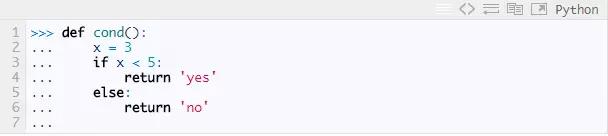
Python在运行时会暴露一大批内部信息,并且我们可以通过REPL直接访问这些信息。对于函数对象cond,cond.__code__是与其关联的code object,而cond.__code__.co_code就是它的字节码。当你写Python代码时,你永远也不会想直接使用这些属性,但是这可以让我们做出各种恶作剧,同时也可以看看内部机制。
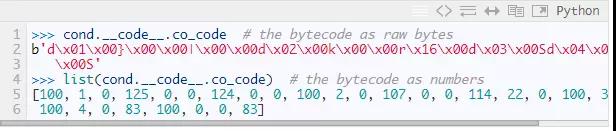
当我们直接输出这个字节码,它看起来完全无法理解 — 唯一我们了解的是它是一串字节。很幸运,我们有一个很强大的工具可以用:Python标准库中的dis module。
dis是一个字节码反汇编器。反汇编器以为机器而写的底层代码作为输入,比如汇编代码和字节码,然后以人类可读的方式输出。当我们运行dis.dis, 它输出每个字节码的解释。
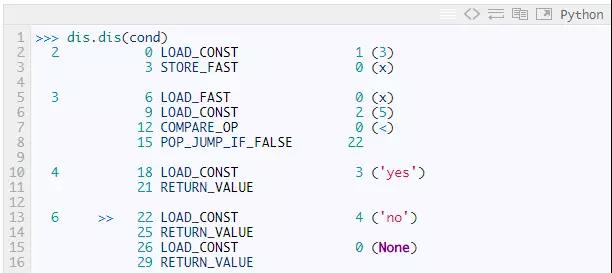
这些都是什么意思?让我们以第一条指令LOAD_CONST为例子。第一列的数字(2)表示对应源代码的行数。第二列的数字是字节码的索引,告诉我们指令LOAD_CONST在0位置。第三列是指令本身对应的人类可读的名字。如果第四列存在,它表示指令的参数。如果第5列存在,它是一个关于参数是什么的提示。
考虑这个字节码的前几个字节:[100, 1, 0, 125, 0, 0]。这6个字节表示两条带参数的指令。我们可以使用dis.opname,一个字节到可读字符串的映射,来找到指令100和指令125代表是什么:

第二和第三个字节 — 1 ,0 —是LOAD_CONST的参数,第五和第六个字节 — 0,0 — 是STORE_FAST的参数。就像我们前面的小例子,LOAD_CONST需要知道的到哪去找常量,STORE_FAST需要找到名字。(Python的LOAD_CONST和我们小例子中的LOAD_VALUE一样,LOAD_FAST和LOAD_NAME一样)。所以这六个字节代表第一行源代码x = 3.(为什么用两个字节表示指令的参数?如果Python使用一个字节,每个code object你只能有256个常量/名字,而用两个字节,就增加到了256的平方,65536个)。
Conditionals and Loops
到目前为止,我们的解释器只能一条接着一条的执行指令。这有个问题,我们经常会想多次执行某个指令,或者在特定的条件下略过它们。为了可以写循环和分支结构,解释器必须能够在指令中跳转。在某种程度上,Python在字节码中使用GOTO语句来处理循环和分支!让我们再看一个cond函数的反汇编结果:
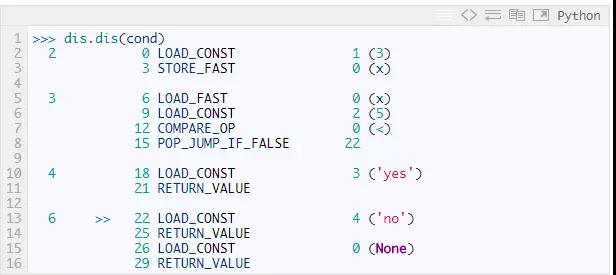
第三行的条件表达式if x < 5被编译成四条指令:LOAD_FAST, LOAD_CONST, COMPARE_OP和 POP_JUMP_IF_FALSE。x < 5对应加载x,加载5,比较这两个值。指令POP_JUMP_IF_FALSE完成if语句。这条指令把栈顶的值弹出,如果值为真,什么都不发生。如果值为假,解释器会跳转到另一条指令。
这条将被加载的指令称为跳转目标,它作为指令POP_JUMP的参数。这里,跳转目标是22,索引为22的指令是LOAD_CONST,对应源码的第6行。(dis用>>标记跳转目标。)如果X < 5为假,解释器会忽略第四行(return yes),直接跳转到第6行(return "no")。因此解释器通过跳转指令选择性的执行指令。
Python的循环也依赖于跳转。在下面的字节码中,while x < 5这一行产生了和if x < 10几乎一样的字节码。在这两种情况下,解释器都是先执行比较,然后执行POP_JUMP_IF_FALSE来控制下一条执行哪个指令。第四行的最后一条字节码JUMP_ABSOLUT(循环体结束的地方),让解释器返回到循环开始的第9条指令处。当 x < 10变为假,POP_JUMP_IF_FALSE会让解释器跳到循环的终止处,第34条指令。

Explore Bytecode
我鼓励你用dis.dis来试试你自己写的函数。一些有趣的问题值得探索:
对解释器而言for循环和while循环有什么不同?
能不能写出两个不同函数,却能产生相同的字节码?
elif是怎么工作的?列表推导呢?
Frames
到目前为止,我们已经知道了Python虚拟机是一个栈机器。它能顺序执行指令,在指令间跳转,压入或弹出栈值。但是这和我们心想的解释器还有一定距离。在前面的那个例子中,最后一条指令是RETURN_VALUE,它和return语句想对应。但是它返回到哪里去呢?
为了回答这个问题,我们必须严增加一层复杂性:frame。一个frame是一些信息的集合和代码的执行上下文。frames在Python代码执行时动态的创建和销毁。每个frame对应函数的一次调用。— 所以每个frame只有一个code object与之关联,而一个code object可以很多frame。比如你有一个函数递归的调用自己10次,这时有11个frame。总的来说,Python程序的每个作用域有一个frame,比如,每个module,每个函数调用,每个类定义。
Frame存在于调用栈中,一个和我们之前讨论的完全不同的栈。(你最熟悉的栈就是调用栈,就是你经常看到的异常回溯,每个以”File ‘program.py'”开始的回溯对应一个frame。)解释器在执行字节码时操作的栈,我们叫它数据栈。其实还有第三个栈,叫做块栈,用于特定的控制流块,比如循环和异常处理。调用栈中的每个frame都有它自己的数据栈和块栈。
让我们用一个具体的例子来说明。假设Python解释器执行到标记为3的地方。解释器正在foo函数的调用中,它接着调用bar。下面是frame调用栈,块栈和数据栈的示意图。我们感兴趣的是解释器先从最底下的foo()开始,接着执行foo的函数体,然后到达bar。
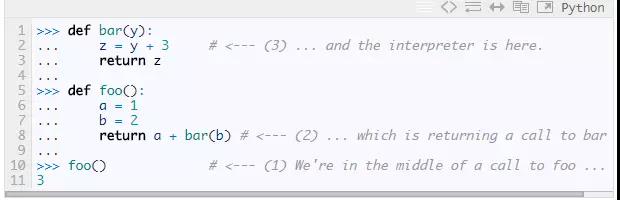
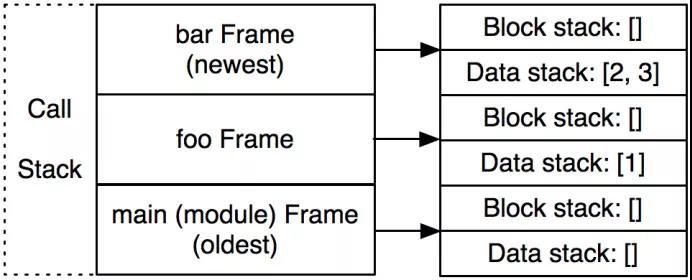
现在,解释器在bar函数的调用中。调用栈中有3个fram:一个对应于module层,一个对应函数foo,别一个对应函数bar。(Figure 1.2)一旦bar返回,与它对应的frame就会从调用栈中弹出并丢弃。
字节码指令RETURN_VALUE告诉解释器在frame间传递一个值。首先,它把位于调用栈栈顶的frame中的数据栈的栈顶值弹出。然后把整个frame弹出丢弃。最后把这个值压到下一个frame的数据栈中。
当Ned Batchelder和我在写Byterun时,很长一段时间我们的实现中一直有个重大的错误。我们整个虚拟机中只有一个数据栈,而不是每个frame都有个一个。我们做了很多测试,同时在Byterun和真正的Python上,为了保证结果一致。我们几乎通过了所有测试,只有一样东西不能通过,那就是生成器。最后,通过仔细的阅读Cpython的源码,我们发现了错误所在。把数据栈移到每个frame就解决了这个问题。
回头在看看这个bug,我惊讶的发现Python真的很少依赖于每个frame有一个数据栈这个特性。在Python中几乎所有的操作都会清空数据栈,所以所有的frame公用一个数据栈是没问题的。在上面的例子中,当bar执行完后,它的数据栈为空。即使foo公用这一个栈,它的值也不会受影响。然而,对应生成器,一个关键的特点是它能暂停一个frame的执行,返回到其他的frame,一段时间后它能返回到原来的frame,并以它离开时的同样的状态继续执行。
Byterun
现在我们有足够的Python解释器的知识背景去考察Byterun。
Byterun中有四种对象。
VirtualMachine类,它管理高层结构,frame调用栈,指令到操作的映射。这是一个比前面Inteprter对象更复杂的版本。
Frame类,每个Frame类都有一个code object,并且管理者其他一些必要的状态信息,全局和局部命名空间,指向调用它的frame的指针和最后执行的字节码指令。
Function类,它被用来代替真正的Python函数。回想一下,调用函数时会创建一个新的frame。我们自己实现Function,所以我们控制新frame的创建。
Block类,它只是包装了代码块的3个属性。(代码块的细节不是解释器的核心,我们不会花时间在它身上,把它列在这里,是因为Byterun需要它。)
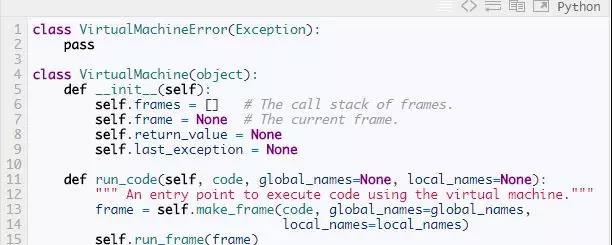
The VirtualMachine Class
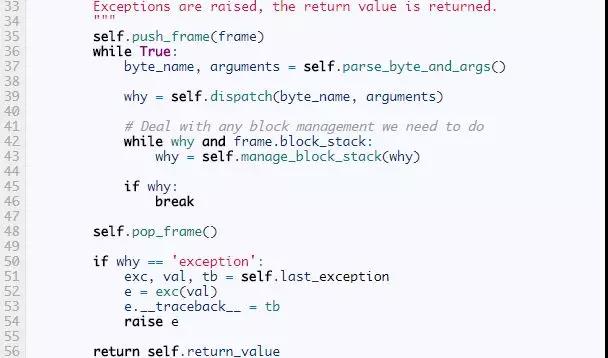
程序运行时只有一个VirtualMachine被创建,因为我们只有一个解释器。VirtualMachine保存调用栈,异常状态,在frame中传递的返回值。它的入口点是run_code方法,它以编译后的code object为参数,以创建一个frame为开始,然后运行这个frame。这个frame可能再创建出新的frame;调用栈随着程序的运行增长缩短。当第一个frame返回时,执行结束。
The Frame Class
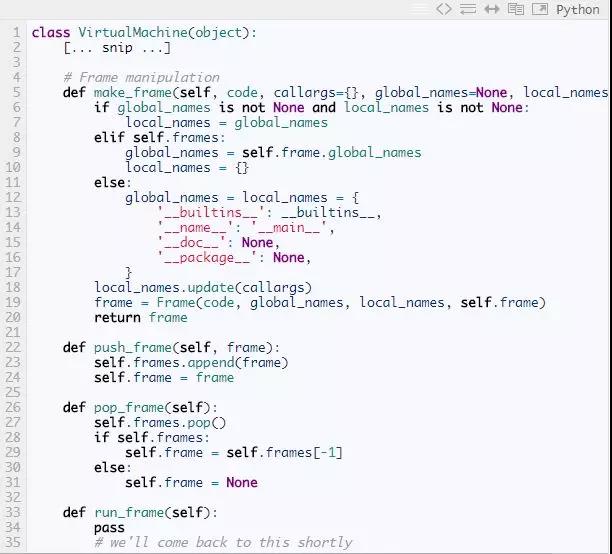
接下来,我们来写Frame对象。frame是一个属性的集合,它没有任何方法。前面提到过,这些属性包括由编译器生成的code object;局部,全局和内置命名空间;前一个frame的引用;一个数据栈;一个块栈;最后执行的指令。(对于内置命名空间我们需要多做一点工作,Python对待这个命名空间不同;但这个细节对我们的虚拟机不重要。)

接着,我们在虚拟机中增加对frame的操作。这有3个帮助函数:一个创建新的frame的方法,和压栈和出栈的方法。第四个函数,run_frame,完成执行frame的主要工作,待会我们再讨论这个方法。
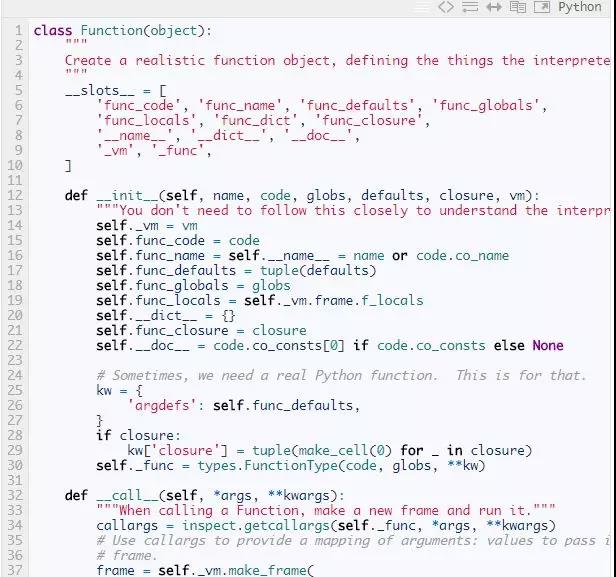
The Function Class
Function的实现有点扭曲,但是大部分的细节对理解解释器不重要。重要的是当调用函数时 — __call__方法被调用 — 它创建一个新的Frame并运行它。
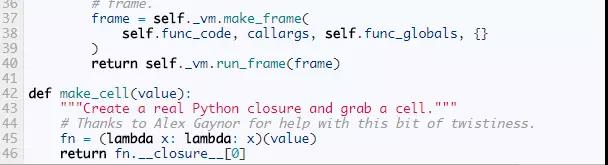
接着,回到VirtualMachine对象,我们对数据栈的操作也增加一些帮助方法。字节码操作的栈总是在当前frame的数据栈。这让我们能完成POP_TOP,LOAD_FAST,并且让其他操作栈的指令可读性更高。

在我们运行frame之前,我们还需两个方法。
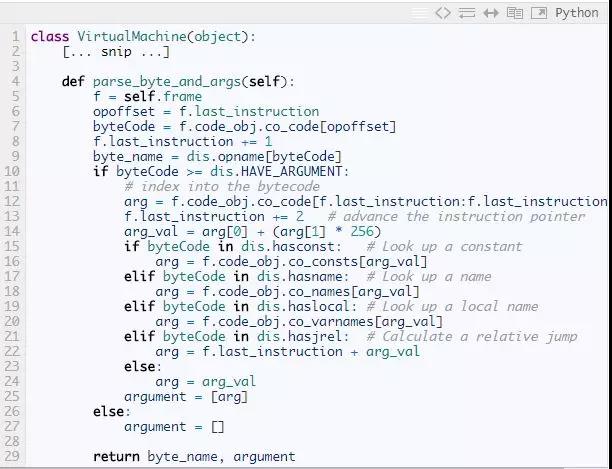
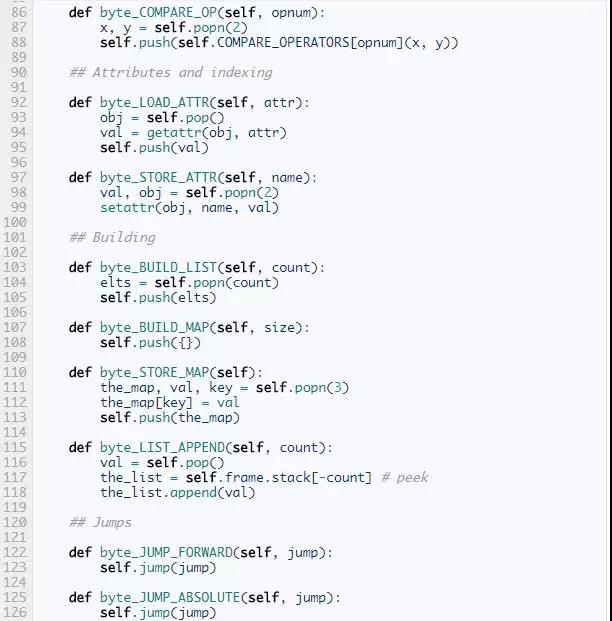
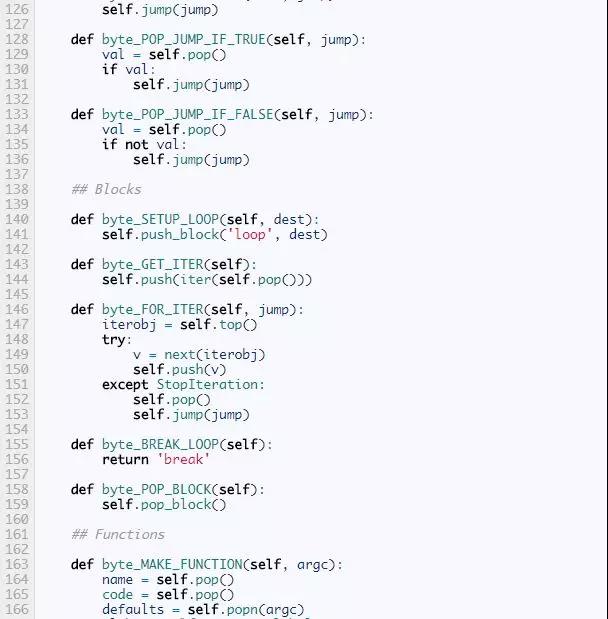
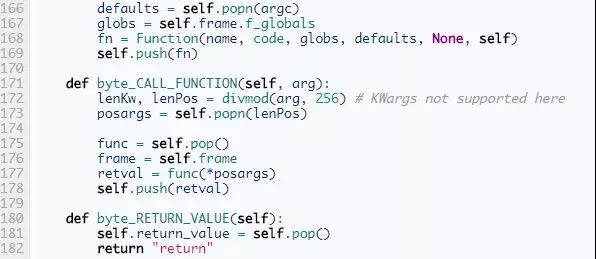
第一个方法,parse_byte_and_args,以一个字节码为输入,先检查它是否有参数,如果有,就解析它的参数。这个方法同时也更新frame的last_instruction属性,它指向最后执行的指令。一条没有参数的指令只有一个字节长度,而有参数的字节有3个字节长。参数的意义依赖于指令是什么。比如,前面说过,指令POP_JUMP_IF_FALSE,它的参数指的是跳转目标。BUILD_LIST, 它的参数是列表的个数。LOAD_CONST,它的参数是常量的索引。
一些指令用简单的数字作为参数。对于另一些,虚拟机需要一点努力去发现它意义。标准库中的dismodule中有一个备忘单解释什么参数有什么意思,这让我们的代码更加简洁。比如,列表dis.hasname告诉我们LOAD_NAME, IMPORT_NAME,LOAD_GLOBAL,和另外的9个指令都有同样的意思:名字列表的索引。
下一个方法是dispatch,它查看给定的指令并执行相应的操作。在CPython中,这个分派函数用一个巨大的switch语句完成,有超过1500行的代码。幸运的是,我们用的是Python,我们的代码会简洁的多。我们会为每一个字节码名字定义一个方法,然后用getattr来查找。就像我们前面的小解释器一样,如果一条指令叫做FOO_BAR,那么它对应的方法就是byte_FOO_BAR。现在,我们先把这些方法当做一个黑盒子。每个指令方法都会返回None或者一个字符串why,有些情况下虚拟机需要这个额外why信息。这些指令方法的返回值,仅作为解释器状态的内部指示,千万不要和执行frame的返回值相混淆。

The Block Class
在我们完成每个字节码方法前,我们简单的讨论一下块。一个块被用于某种控制流,特别是异常处理和循环。它负责保证当操作完成后数据栈处于正确的状态。比如,在一个循环中,一个特殊的迭代器会存在栈中,当循环完成时它从栈中弹出。解释器需要检查循环仍在继续还是已经停止。
为了跟踪这些额外的信息,解释器设置了一个标志来指示它的状态。我们用一个变量why实现这个标志,它可以None或者是下面几个字符串这一,"continue", "break","excption",return。他们指示对块栈和数据栈进行什么操作。回到我们迭代器的例子,如果块栈的栈顶是一个loop块,why是continue,迭代器就因该保存在数据栈上,不是如果why是break,迭代器就会被弹出。
块操作的细节比较精密,我们不会花时间在这上面,但是有兴趣的读者值得仔细的看看。


The Instructions
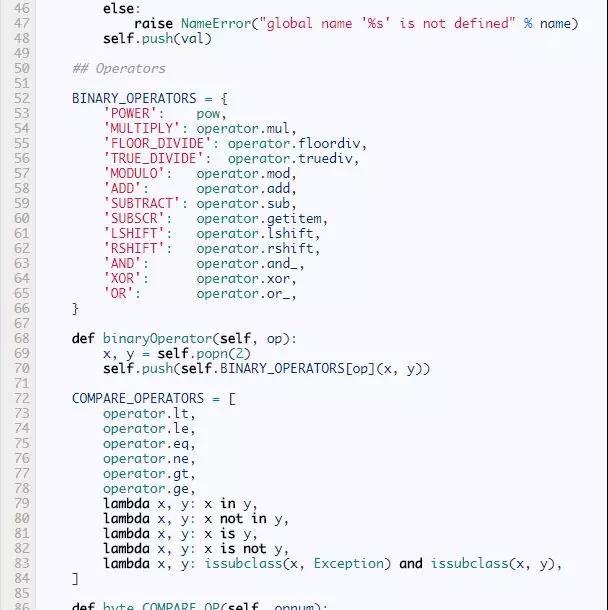
剩下了的就是完成那些指令方法了:byte_LOAD_FAST,byte_BINARY_MODULO等等。而这些指令的实现并不是很有趣,这里我们只展示了一小部分,完整的实现在这儿(足够执行我们前面所述的所有代码了。)

Dynamic Typing: What the Compiler Doesn’t Know
你可能听过Python是一种动态语言 — 是它是动态类型的。在我们建造解释器的过程中,已经流露出这个描述。
动态的一个意思是很多工作在运行时完成。前面我们看到Python的编译器没有很多关于代码真正做什么的信息。举个例子,考虑下面这个简单的函数mod。它区两个参数,返回它们的模运算值。从它的字节码中,我们看到变量a和b首先被加载,然后字节码BINAY_MODULO完成这个模运算。
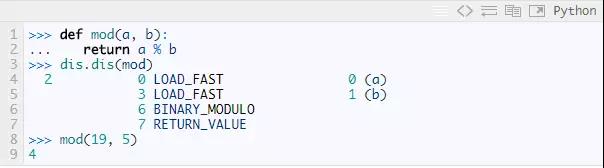
计算19 % 5得4,— 一点也不奇怪。如果我们用不同类的参数呢?

刚才发生了什么?你可能见过这样的语法,格式化字符串。

用符号%去格式化字符串会调用字节码BUNARY_MODULO.它取栈顶的两个值求模,不管这两个值是字符串,数字或是你自己定义的类的实例。字节码在函数编译时生成(或者说,函数定义时)相同的字节码会用于不同类的参数。
Python的编译器关于字节码的功能知道的很少。而取决于解释器来决定BINAYR_MODULO应用于什么类型的对象并完成真确的操作。这就是为什么Python被描述为动态类型:直到你运行前你不必知道这个函数参数的类型。相反,在一个静态类型语言中,程序员需要告诉编译器参数的类型是什么(或者编译器自己推断出参数的类型。)
编译器的无知是优化Python的一个挑战 — 只看字节码,而不真正运行它,你就不知道每条字节码在干什么!你可以定义一个类,实现__mod__方法,当你对这个类的实例使用%时,Python就会自动调用这个方法。所以,BINARY_MODULO其实可以运行任何代码。
看看下面的代码,第一个a % b看起来没有用。

不幸的是,对这段代码进行静态分析 — 不运行它 — 不能确定第一个a % b没有做任何事。用 %调用__mod__可能会写一个文件,或是和程序的其他部分交互,或者其他任何可以在Python中完成的事。很难优化一个你不知道它会做什么的函数。在Russell Power和Alex Rubinsteyn的优秀论文中写道,“我们可用多快的速度解释Python?”,他们说,“在普遍缺乏类型信息下,每条指令必须被看作一个INVOKE_ARBITRARY_METHOD。”
Conclusion
恭喜你阅读完了“用Python 编写的 Python 解释器,确定吗?”这篇文章,你确定了吗?不知道你现在是想要逗号、句号、问号还是叹号来表达你的想法?Byterun是一个比CPython容易理解的简洁的Python解释器。Byterun复制了CPython的主要结构:一个基于栈的指令集称为字节码,它们顺序执行或在指令间跳转,向栈中压入和从中弹出数据。解释器随着函数和生成器的调用和返回,动态的创建,销毁frame,并在frame间跳转。Byterun也有着和真正解释器一样的限制:因为Python使用动态类型,解释器必须在运行时决定指令的正确行为。我鼓励你去反汇编你的程序,然后用Byterun来运行。你很快会发现这个缩短版的Byterun所没有实现的指令。完整的实现在这里或者仔细阅读真正的CPython解释器ceval.c,你也可以实现自己的解释器!还想了解更多关于python的知识,解决python方面的相关疑惑,来达内python培训班获取吧!
免责声明:内容和图片源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



