

Python培训
400-996-5531
400-996-5531
很多小伙伴让我写Python进阶技巧的文章,其实Python的进阶我觉得主要在对一些库的熟练使用,另外对代码的驾驭能力(小密圈后面会分享一些心得).个人觉得比较好的方法多看库,然后多读GitHub 上的源码,对你的进阶之路大有裨益!今天就来分享几个我平时非常喜欢的库,并详细举例说明,希望对大家有帮助!
工具:Sublime Text
语言:Python3.6
高手必知的库:
collections
concurrent
logging
argparse
我最喜欢的collections库
大家知道Python里面的字典虽然好用,但是有两个显著的缺点,其中之一就是无序,如何在构造字典的时候,让字典里面填入的内容有序呢,一般的方法都是等字典的内容填充好了之后,用sorted排序,但是sorted,也并不能保证是按照添加的顺序进行迭代
痛点1:字典无序的问题
有没有办法让字典出生的时候就是带序的,有的就是collections库里面的OrderedDict,传统的字典输出的时候,有时会乱序

>>{'A': 0, 'B': 1, 'C': 2, 'E': 4, 'D': 3}
如果我们想按照字典加入的顺序输出,必须用OrderedDict

OrderedDict会自动按照加入的顺序打印,但是这样做的坏处是开销很大,因为它内部维护了一张双向链表,大小是普通字典的2倍.
痛点2:字典无缺省值的问题
字典一般都是没有缺省值的,比如我们在爬虫的时候,我们希望我们爬取的关键字如果爬到有值则填入内容,如果没有则用缺省值代替.
比如我前段时间做的年度电影榜单(2017年度电影榜单出炉),keys=['movie_name','movie_link','rating_num','rating_people_num']
初始化这样的字典有三种方法:
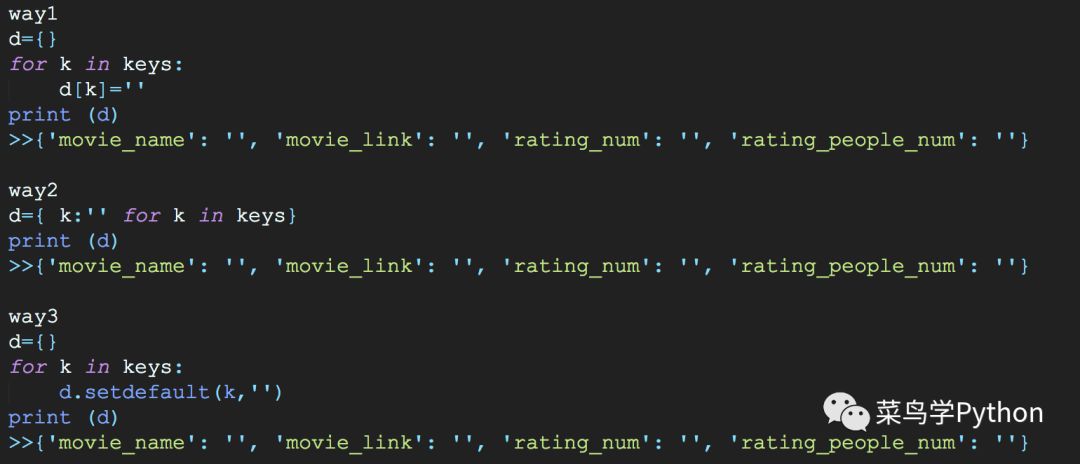
但是上面3种解决方案有缺点:
比如我们访问一个不存在的key的时候,如何让它返回一个缺省值 ?
比如复杂一点数据结构,字典里面有列表,而不是一个简单的字符串?
这些问题如何优雅的解决,用神器defaultdict
比如我们构造一个学生的成绩单,缺省值我们认为是60分:

如果我们要获取一个不在名单里面的学生成绩
print (students['sam'])
>>60 #输出是60
我们打印一些看看学生的成绩,是不是非常方便
print (students)
>>{'lili': 100, 'jack': 80, 'tom': 70, 'sam': 60})
如果我们是一个字典嵌套集合的数据结构,我们只要把这个字典缺省设为set,然后只要管如何添加数据就行,不用操心如何初始化字典:

痛点3:像类一样玩转元组数据
比如我们有一个数据结构students = (name, score, weight)
我们要访问这个元组,需要通过下标去访问,非常不方便,如果这个元组很长,用下标会弄错,而且乱序之后不易扩展
如果用一个类去构建,有点杀鸡用牛刀的赶脚!这个时候用namedtuple就有一种妙不可言的感觉,太方便了,可以体会一下Python之美.

然后我们访问这个属性,可以用类似类的访问属性方式去访问
print (s1.name)
print (s1.score)
print (s1.weight)
>>
Leo
100
65
简单而强大的并发库concurrent
痛点4:如何简便的用并发
我们在爬虫的时候,如果有100个url需要并发去爬取,一种通用的做法是开多线程,然后把100个url放入队列里面,开多线程从共享队列里面取url并发爬取,有没有更简便的方便,有的用concurrent库.
比如:我们有一个需求是要爬取百度,头条,知乎,豆瓣,新浪和搜狐的首页.
我们看用concurrent里面的线程池如何轻松解决
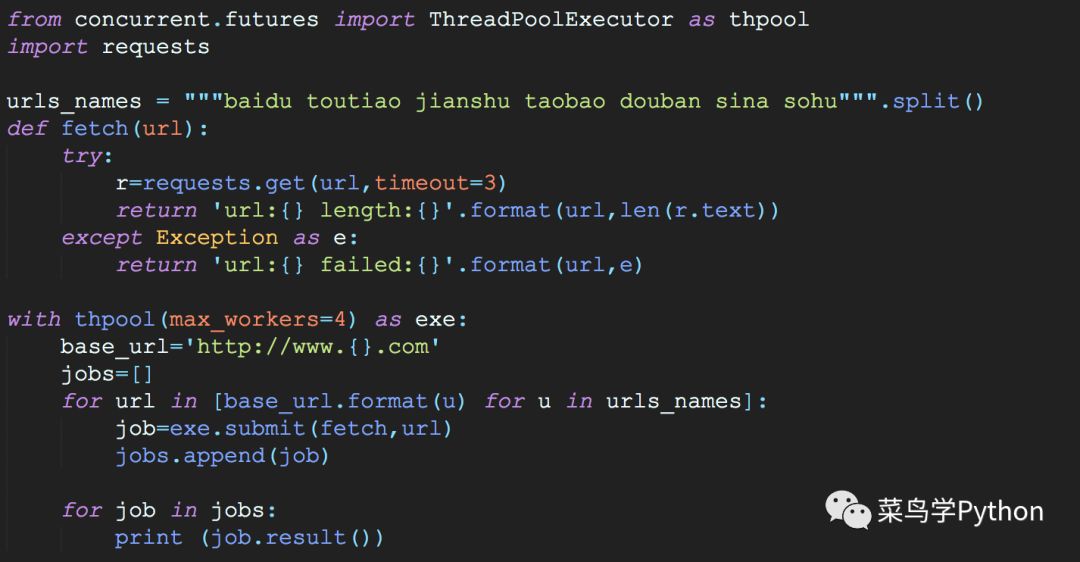
>>
url:http://www.baidu.com length:2381
url:# length:7137
url:# length:48378
url:# length:126311
url:# length:91297
url:# length:605568
url:http://www.sohu.com length:191148
直接用ThreadPoolExecutor一个线程池的管理器来负责,thpool(max_workers=4)来创建一个线程池,你可以自己定义多个线程一起并发,然后用submit来往线程池里面添加task,是不是很简便!
全能的日志库logging
痛点5:日志怎么打才好
在做大一点的项目的时候,有3个地方需要考虑:
第一:代码架构的扩展性和维护性,主要会用一些设计模式来重构
第二:代码的稳定性,会加很多异常保护
第三:就是头疼的debug的日志,需求既要灵活,功能又要全面
单一的print非常lower,为了解决这个痛点,我们必须用logging模块
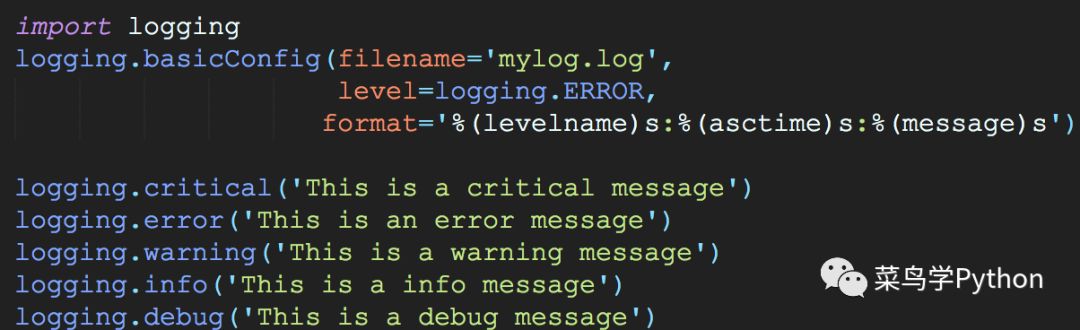
>>这个时候我们去看一下mylog.log文件就会发现,里面把这5条信息都记录下来了
CRITICAL:root:This is a critical message
ERROR:root:This is an error message
WARNING:root:This is a warning message
INFO:root:This is a info message
DEBUG:root:This is a debug message
logging里面有5个级别critical>error>warning>info>debug
debug是最低的,我们上面在basciConfig里面设置的是低优先级的DEBUG,如果我们改成WARNING,那么就只显示warning以上的级别(含warning)
如果我们想输出的日志里面加时间戳,怎么办,简单的在basicConfig里面设置一下format格式就ok了
%(levelname)s: 打印日志级别名称
%(asctime)s: 打印日志的时间
%(message)s: 打印日志信息

多面的命令行解析库
痛点6:解决命令行解析多选项问题
如果有做命令行的同学,或者是自动化脚本的对argparse一定不陌生,这个一个非常重要的库,可以对命令行提供强大的各种选项功能
比如新建一个demo.py ,我们希望这个小脚本可以对两个数运算

我们在命令行下敲一下:
xindeMacBook-Pro:HiPython xin$ python3 demo.py -h
usage: demo.py [-h] [-t T] [-n1 N1] [-n2 N2]
calculate two numbers
optional arguments:
-h, --help show this help message and exit
-t T add/mul
-n1 N1 First num
-n2 N2 Second num
-h立马就把各个选项的用法一目了然
-t 表示你运算类型
-n1表示第一个数
-n2表示第二个数
输入add作加法运算:
xindeMacBook-Pro:HiPython xin$ python3 demo.py -t add -n1 10 -n2 20
10.0+20.0=30.0
输入mul作乘法运算:
xindeMacBook-Pro:HiPython leoxin$ python3 demo.py -t mul -n1 10 -n2 20
10.0*20.0=200.0
结论:
所有的高手都是从菜鸟一步一步走过来的,不断的吸取养分,保持如饥似渴的学习热情,多思考,总有一天菜鸟会展翅高飞成为一代高手! Python的实践性非常强,希望上面几个库可以给大家一些思路和参考,我们继续前行.
本文内容转载自网络,来源/作者信息已在文章顶部表明,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



