

Python培训
400-996-5531
400-996-5531
什么是文本分类
一个文本分类问题就是将一篇文档归入预先定义的几个类别中的一个或几个。通俗点说,就是拿一篇文章,问计算机这文章要说的究竟是体育,经济还是教育。文本分类是一个监督学习的过程,常见的应用就是新闻分类,情感分析等等。其中涉及到机器学习,数据挖掘等领域的许多关键技术:分词,特征抽取,特征选择,降维,交叉验证,模型调参,模型评价等等,掌握了这个有助于加深对机器学习的的理解。这次我们用python的scikit-learn模块实现文本分类。
文本分类的过程
首先是获取数据集,为了方便,我们直接使用scikit-learn的datasets模块自带的20类新闻数据集,并且取了其中四个类别的新闻

从datasets获取到一般都是一个Bunch对象,Bunch是一种类似于python字典的格式,我们拿到任何一个数据集之后都可以探索数据集,输出Bunch对象的键keys看看有什么,看看数据集的描述,数据的内容等等。
接下来就要进行分词和去停用词,分词就是将句子切分成单词,这些词语就是后面用来训练模型的特征。切分成单词之后就要去除停用词,停用词一些无意义的词,比如‘the’,‘a’这些词对于文本分类没有帮助,网上可以找到中英文的停用词表来帮助去掉停用词。由于英文句子中的单词之间有空格,所以英文分词十分简单。如果处理的是中文语料,jieba分词可以帮助我们方便地进行中文分词。除了分词之外,中英文文本分类处理基本上是一样的。
计算机怎么读懂文本呢,接下来进就需要行文本表示,我们常用向量空间模型(VSM)。简单的解释VSM模型,例如,经过分词后得到文档1={ABBCD},标记为1类,文档2={BAACE},标记为0类。我们得到所有文档共享的一个文档词典{A,B,C,D,E},那么对应的VSM就可以表示为文档1表示为[1,2,1,1,0],文档2表示为[2,1,1,0,1]其中权重是每个词出现的次数。权重也可以是bool值,出现为1,不出现为0,不考虑出现次数;也可以用tf-idf值表示,tf-idf简单来说就是存在一个词语A,它在每篇文档中出现的次数越多,并且在越少的文档中出现,那么tf-idf值就越大。VSM模型表示方法的优点就是简单,便于理解,缺点是丢失了词与词之间的前后顺序信息。

这里用的是scikit-learn中的feture_extraction.text.CountVectorizer模块,就是从文本中抽取特征,两行代码实现了分词,去除停用词,建立VSM模型,得到的X就是VSM模型的矩阵,就是这么方便强大,这里的min_df用来降维,下面会提到。如果是处理中文语料,那么我们就需要提前分词,去除停用词,然后就可以用CountVectorize来得到VSM模型的矩阵了。
建立了向量空间模型后,首先面对的问题就是VSM的矩阵维数太大,我们训练集有2034篇文档,得到的VSM是2034*33814维,而如果文档比较多的话,文档词典的词语个数很容易会达到几十万个。我们需要进行降维处理,一方面可以让模型训练更快,同时也能够增加模型泛化能力。在文本处理中,常用的降维方法有文档频数法(document frequency, df),卡方检验,互信息法。df降维认为特征在越多文本中出现,对分类作用越大,实验证明,df虽然简单,却相当有效。我们已经在上面实现了,就是‘min_df=2’这个参数,含义就是若某个词语只在一篇文档中出现,我们就把它从文档词典中去掉,当然这个值可以设的再大一些。经过df降维后,特征由33814降到了17264维。
卡方检验,卡方值描述了自变量与因变量之间的相关程度:卡方值越大,相关程度也越大,所以很自然的可以利用卡方值来做降维,保留相关程度大的变量。用前面的例子,现在文档词典是{A,B,C,D,C,E},VSM模型矩阵为[[1,2,1,1,0],[2,1,1,0,1]],对应的类别y为[1,0]。也就是特征A的值为[1,2],来和y[1,0]计算一个卡方值,接下来计算B,C,D,E的卡方值,然后我们选择前K个卡方值大的变量,进行特征降维。互信息法也是一样的,互信息描述了两个分布之间相关程度,只是和卡方的计算公式不同。我们认为和y相关度越大,越有利于分类。
没有搞懂卡方检验和互信息法也没有关系,scikit-learn为我们提供了模块可以很方便的进行计算。
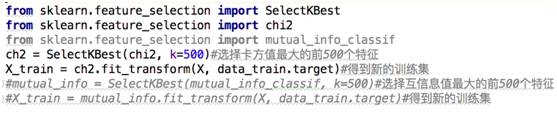
接下来就可以训练模型了,从文本分类实践来看,最好的文本分类的机器学习算法可以说就是SVM了 。代码如下:

首先我们对测试集data_test.data建立VSM模型,不用担心这样会出什么问题,使用vectorizer.transform(data_test.data)可以保证测试集和训练集的文档字典是一致的,用前面的例子来讲,训练集的文档词典是{A,B,C,D,E},无论测试集中含有什么新的单词,我们仍然保证测试集的文档词典是{A,B,C,D,E},这样才是有意义的。同样的,对测试集的卡方检验也会选出和训练集一样的特征。
网格搜索GridSearch调参,听起来很高大上,其实就是暴力搜索,我们这里为SVC的kernel 和C分别提供了两个值,那么就会有4个组合,分别进行训练,挑出最优的。这里的cv就是cross_validate,交叉验证,cv=5就是5折交叉验证,后面的score参数说的是我们选出的模型是准确率得分最高的,当然可以有其它评价标准。在scikit-learn中交叉验证属于模型选择模块,可能有的同学会不理解交叉验证和模型选择有什么关系,用这里的5折交叉验证举例说明
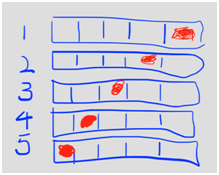
将样本分成5份,用涂成红色作为测试,其余4组作为训练,模型1是SVC(kerner=’linear’,C=0.1),可以训练5次,每次训练都可以得到一个准确率的值,然后对5次求平均就得到了模型1的得分。模型2 SVC(kerner=’linear’,C=1),模型3 SVC(kerner=’poly’,C=0.1),模型4 SVC(kerner=’poly’,C=1)同理。最后我们从这4个种选出得分最高的模型,作为最终的模型,这就是交叉验证在模型选择中起到的作用。
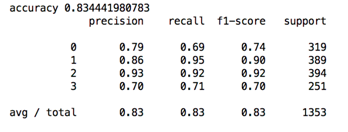
最后就是模型评价,一般来说准确率(accuracy)很常用,但是对于不均衡样本,看准确率实际上没什么价值。假设测试集有100个样本10个正样本,90个负样本,那即使全部预测为负样本,仍然能得到90%的准确率,但是这是没有价值的。我们可以引入精确率(precision),召回率(recall)和f1值来评价分类模型,也可以通过roc曲线和auc的值来分析。

最终得到的结果如下:
总结
如何提升结果呢?我们可以使用2-gram模型,举例来说,“Don’t tase me, bro” 如果是1-grams, “don’t,” “tase,” “me,” 和“bro.” 如果是 2-grams ,得到“don’t tase”, “tase me”和 “me bro.”这样保留了相邻的词语顺序信息,不过这样会产生更多的特征。还有我们可以把VSM模型中的权值改为bool值,或者tf-idf值,来看看效果是否有提升,这些用scikit-learn都可以很方便的实现。
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



