

Python培训
400-996-5531
400-996-5531
很多公司的员工辞职之前人事部门和上级领导可能都没有察觉到,等到员工提出了要辞职之后才想办法去挽留。
那么我们有没有什么方法可以提前预测出可能离职的员工并进行提前的沟通,从而避免这样的事情发生呢?
现在我们就来根据一些相关的指标和员工离职相关的因素来计算他们辞职的概率并进行相应的预测以便提前做出预判。
一、数据预览
首先,我们先导入相应的库,并进行数据的初步预览:
#首先导入相应的库 import pandas as pd import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn import svm from sklearn import tree from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score from sklearn.naive_bayes import GaussianNB from sklearn import cross_validation import matplotlib.pyplot as plt import seaborn as sns from subprocess import check_output import warnings warnings.filterwarnings('ignore') sns.set_style('whitegrid') import matplotlib font = {'family':'SimHei'} matplotlib.rc('font',**font) matplotlib.rcParams['axes.unicode_minus']=False %matplotlib inline#读取文件 df = pd.read_csv(r'C:\Users\Administrator\Desktop\HR_comma.csv') print('Number of records:',df.shape[0])

(1)检查缺失值

数据很干净,没有发现缺失值。
(2)查看数据的类型
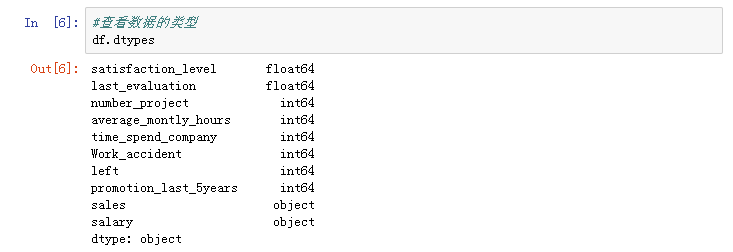
(3)更改部分数据显示形式
我们后续需要对工资列的数据进行分析,因此我们先将其转换成数值以便后续的分析。

现在让我们对数据的整体情况进行简单的了解:

二、数据可视化
我们先来看看相关的数据矩阵:
#我们先看看相关矩阵 f,ax = plt.subplots(figsize=(9,6))
corr = df.corr()
sns.heatmap(corr,annot=True,cmap='seismic')
ax.set_xticklabels(corr.columns.values)
ax.set_yticklabels(corr.columns.values)
ax.set_title('相关矩阵热图',fontsize=16, position=(0.5,1.02))
ax.tick_params(labelsize=15,colors = 'black')
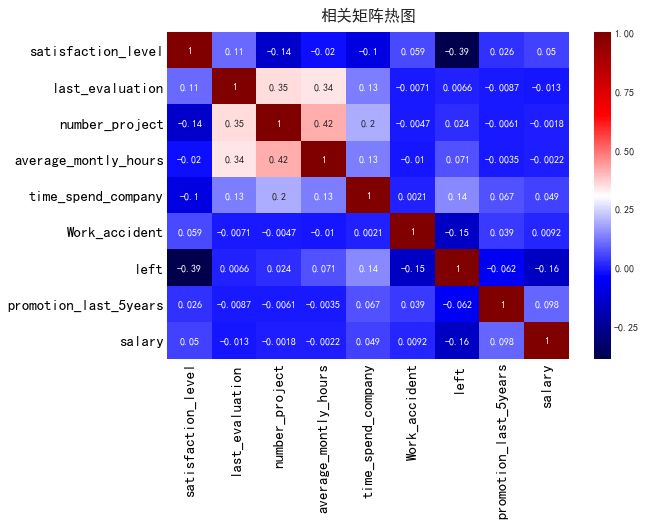
可以看出离职的员工和员工对公司的满意度有着明显的负相关。
现在我们使用核密度图和直方图来进行相关特征的的分析:
#离职和在职员工对公司的评价和满意度 f,(ax1,ax2) = plt.subplots(figsize=(15,9),ncols=2)
ax1.plot(df.satisfaction_level[df.left==1],df.last_evaluation[df.left==1],'ro',alpha=0.2)
ax1.set_xlabel('满意度',fontsize=20)
ax1.set_ylabel('上次评价',fontsize=20)
ax1.set_title('Employees who left',fontsize=20)
ax1.tick_params(labelsize=15)
ax2.plot(df.satisfaction_level[df.left==0],df.last_evaluation[df.left==0],'bo',alpha=0.2)
ax2.set_xlim([0.4,1])
ax2.set_xlabel('满意度',fontsize=20)
ax2.set_ylabel('上次评价',fontsize=20)
ax2.set_title('Employees who stayed',fontsize=20)
ax2.tick_params(labelsize=15,colors = 'black')
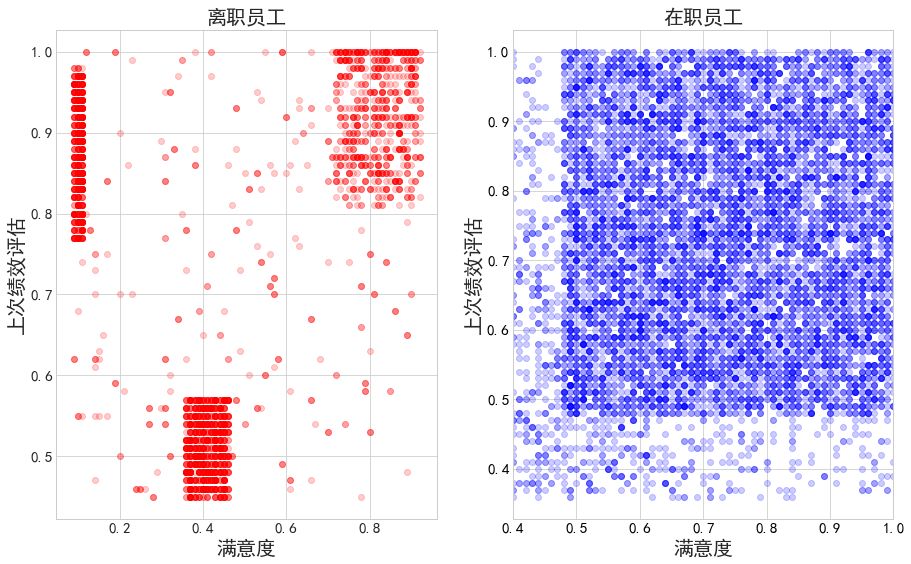
可以看出在离职的员工当中,对公司有满意也有不满意的,在绩效评估方面有绩效不好的也有绩效很好的。
接下来我们进行更进一步的分析,为了方便分析,我们将离职的员工进行集群的划分:
快乐和感激,我们称他们为“赢家”,那些离开的人,是因为他们得到了更好的机会(胜利者)。
被欣赏但不快乐的人,也许他们太适合这份工作了导致公司的平台不足以让他们有更好的发挥(失意者)。
不受赏识和不快乐的人会离开,这并不奇怪,这也不是公司所需要的员工(不合适)。
现在我们使用以上的分类来进行集群的划分与可视化:
#离职的员工的三种类型集群图 from sklearn.cluster import KMeans
kmeans_df = df[df.left==1].drop([u'number_project',u'average_montly_hours',
u'time_spend_company',u'Work_accident',u'left',
u'promotion_last_5years',u'sales',u'salary'],axis=1)
kmeans = KMeans(n_clusters=3,random_state=0).fit(kmeans_df)
print(kmeans.cluster_centers_)
left=df[df.left==1]
left['label'] = kmeans.labels_
f,ax4=plt.subplots(figsize=(12,8))
ax4.set_xlabel('Satisfaction Level', fontsize=15)
ax4.set_ylabel('Last Evaluation score', fontsize=15)
ax4.set_title('离职的员工的三种类型集群', fontsize=15, position=(0.5,1.05))
ax4.plot(left.satisfaction_level[left.label==0], left.last_evaluation[left.label==0], 'o', alpha=0.2, color='r')
ax4.plot(left.satisfaction_level[left.label==1], left.last_evaluation[left.label==1], 'o', alpha=0.2, color='g')
ax4.plot(left.satisfaction_level[left.label==2], left.last_evaluation[left.label==2], 'o', alpha=0.2, color='b')
ax4.tick_params(labelsize=15, colors = 'black')
ax4.legend(['胜利者','失意者','不匹配者'], loc = 'best', fontsize = 15, frameon = True)
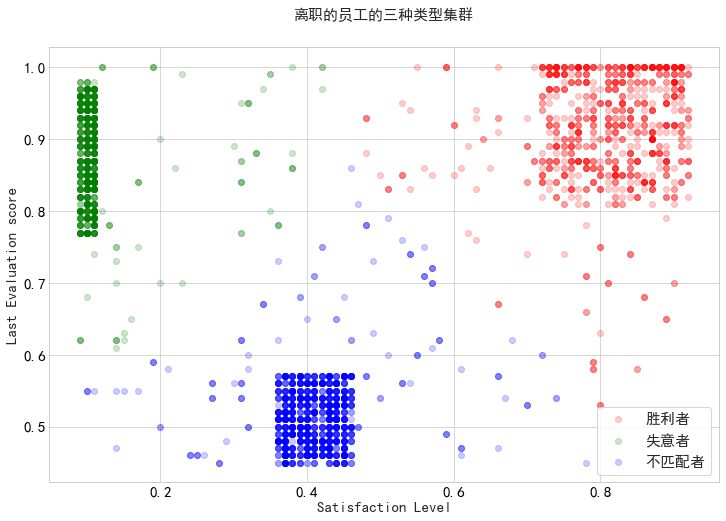
对离职员工进行集群的划分,以便于后续的分析。
我们看看不同集群当中的离职的员工每个月工作时间情况:
#离职员工对公司满意度情况与工作时间关系图 winners = left[left.label==0]
frustrated = left[left.label==1]
bad_match = left[left.label==2]
f,ax5 = plt.subplots(figsize=(12,5))
sns.kdeplot(winners.average_montly_hours, color='r', shade=True)
sns.kdeplot(frustrated.average_montly_hours, color='g', shade=True)
sns.kdeplot(bad_match.average_montly_hours, color='b', shade=True)
ax5.set_ylim([0,0.03])
ax5.legend(['胜利者','失意者','不匹配者'])
ax5.set_title('离职员工每月工作时间',fontsize=15,position=(0.5,1.05))
ax5.tick_params(labelsize=15, colors = 'black')
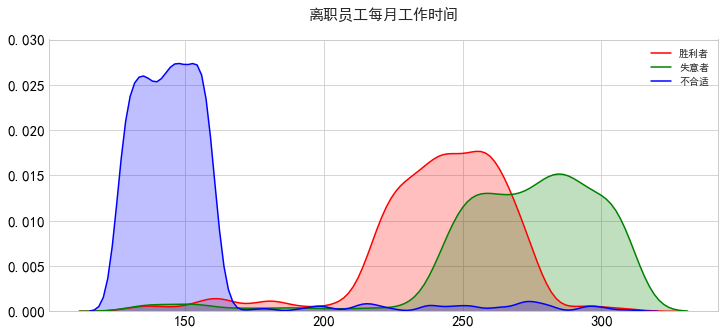
我们可以看出不得意的那部分人的工作时间太长了,而不合适的那些人的工作时间则太少了,满意的人工作时间属于适中的。
(1)员工满意度
现在,我们将对在职和离职的员工使用直方图或核密度估计图来对几个相关的特征分布进行可视化处理。
#生成内核密度估计图和直方图以查看每个特征 f,ax6 = plt.subplots(figsize=(10,5))
sns.kdeplot(df.loc[(df['left']==0), 'satisfaction_level'], color='r', shade=True, label='在职')
sns.kdeplot(df.loc[(df['left']==1), 'satisfaction_level'], color='b', shade=True, label='离职') #ax6.legend(['满意','离职']) ax6.set_title('员工满意度',fontsize=15,position=(0.5,1.05))
ax6.tick_params(labelsize=15, colors = 'black')
ax6.set_ylim([0,3])

“满意程度”可以说是鉴别公司的员工是否会离职的一个很好特征指标,离开的人普遍对自己的工作不满。不过,也有一些人对自己的工作很满意,但还是离开了,这意味着除了对工作满意之外,还有其他因素会影响员工离职。
(2)上次绩效评估情况
#上次绩效评估指标对员工离职的影响 f,ax7 = plt.subplots(figsize=(12,5))
sns.kdeplot(df.loc[(df['left']==0), 'last_evaluation'], color='r', shade=True, label='在职')
sns.kdeplot(df.loc[(df['left']==1), 'last_evaluation'], color='b', shade=True, label='离职') #ax6.legend(['满意','离职']) ax7.set_title('上次的业绩评估', fontsize=15, position=(0.5,1.05))
ax7.tick_params(labelsize=15, colors = 'black')
ax7.set_ylim([0,3.5])

看起来那些离开公司的人在上次的业绩评估中表现得很差或者很好,在离开的人中,没有多少中等水平的员工。如果一个员工的评估分数在0.6到0.8的范围内,他们很可能仍然留在公司工作。
(3)负责的项目数量
#负责的项目数量的多少对员工离职情况的影响 f,ax8 = plt.subplots(figsize=(12,5))
sns.kdeplot(df.loc[(df['left']==0), 'number_project'], color='r', shade=True, label='在职')
sns.kdeplot(df.loc[(df['left']==1), 'number_project'], color='b', shade=True, label='离职') #ax6.legend(['满意','离职']) ax8.set_title('项目数量', fontsize=15, position=(0.5,1.05))
ax8.tick_params(labelsize=15, colors = 'black') #ax8.set_ylim([0,3.5])
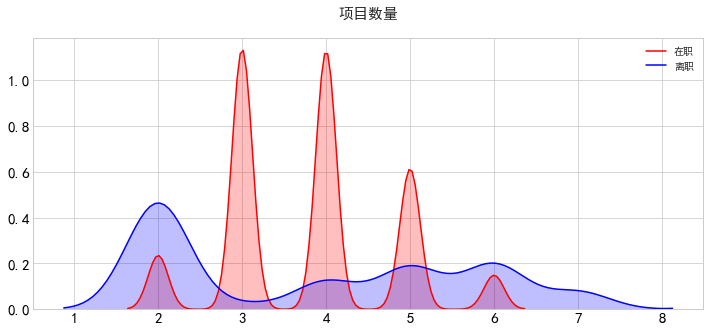
离开的人主要从事少数项目(2),或大量的项目(5-7)。我增加了一个新功能:每年的项目数量,我将其定义为员工在其受雇期间工作的项目数量,除以员工在公司工作的总年数。与那些没有离开的员工相比,那些离开的人每年的项目数量较少。
(4)平均每月工作时间
#平均每月工作时间对员工离职情况的影响 f,ax9 = plt.subplots(figsize=(12,5))
sns.kdeplot(df.loc[(df['left']==0), 'average_montly_hours'], color='r', shade=True, label='在职')
sns.kdeplot(df.loc[(df['left']==1), 'average_montly_hours'], color='b', shade=True, label='离职') #ax9.legend(['满意','离职']) ax9.set_title('平均每月工作时间', fontsize=15, position=(0.5,1.05))
ax9.tick_params(labelsize=15, colors = 'black')
ax9.set_ylim([0,0.012])
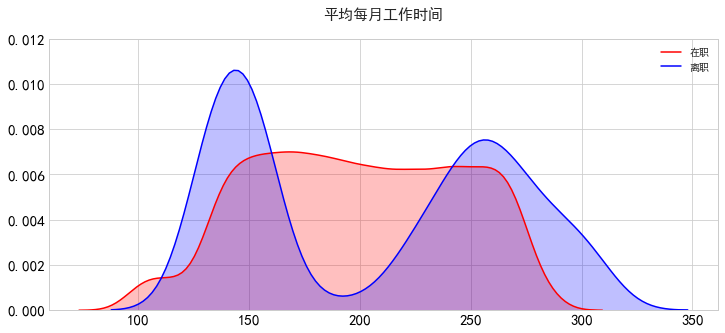
离职的人平均每月工作时间很少(低于150小时),或者工作时间很长(超过250小时)。这意味着离职的员工要么工作不太好,要么工作得很卖力,离职的员工在最后一次业绩评估中要么表现糟糕,要么表现良好,这可能与这一事实有很大的关系。
(5)工资水平
#工资水平对员工离职情况的影响 f,ax10 = plt.subplots(figsize=(12,5))
sns.kdeplot(df.loc[(df['left']==0), 'salary'], color='r', shade=True, label='在职')
sns.kdeplot(df.loc[(df['left']==1), 'salary'], color='b', shade=True, label='离职') #ax10.legend(['满意','离职']) ax10.set_title('员工工资水平', fontsize=15, position=(0.5,1.05))
ax10.tick_params(labelsize=15, colors = 'black')
ax10.set_ylim([0,2.5])

我们可以清楚地看到这里的趋势——薪水越高,员工离开的概率就越低。
(6)工作时间
#工作时间对员工离职情况的影响 f,ax11 = plt.subplots(figsize=(10,4))
sns.barplot(x='time_spend_company', y='left', data = df, saturation=1)
ax11.set_title('员工离职时间分布图', fontsize=15, position=(0.5,1.05))
ax11.tick_params(labelsize=15, colors = 'black')
ax11.set_xlabel('在公司工作时间', fontsize=15)
ax11.set_ylabel('离职比例', fontsize=15)
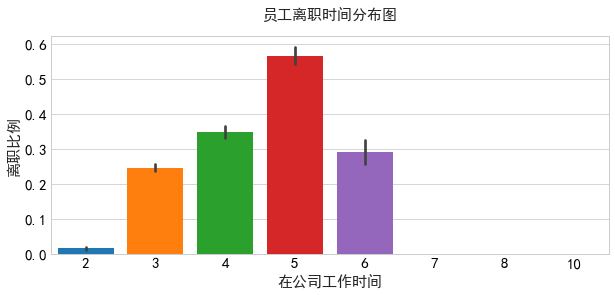
大多数的员工在五年左右离职。
三、数据建模
进行数据建模之前我们先将数据分解为训练和测试集:

(1)朴素贝叶斯
#创建朴素贝叶斯分类器 clf_gb = GaussianNB()
clf_gb.fit(X_train, y_train)
predicts_gb = clf_gb.predict(X_test)
print('GB Accuracy Rate, which is calculated by accuracy_score() is: %f' % accuracy_score(y_test, predicts_gb)) #输出: GB Accuracy Rate, which is calculated by accuracy_score() is: 0.828533(2)K-NN算法
#创建 k-nn knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print('KNN Accuracy Rate, which is calulated by accuracy_score() is: %f' % accuracy_score(y_test, y_pred)) #输出: KNN Accuracy Rate, which is calulated by accuracy_score() is: 0.930933让我们来优化一下KNN模型:
#优化KNN模型 k_range = range(1,26)
scores = [] for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
scores.append(accuracy_score(y_test, y_pred))
plt.plot(k_range,scores)
plt.title('K邻近算法',fontsize=15)
plt.xlabel('Value of k for KNN',fontsize=15)
plt.ylabel('测试精度',fontsize=15)
plt.tick_params(labelsize=12, colors = 'black')

可以发现进行相应的优化之后效果并不是我们想要的。
(3)决策树
#decision tree决策树 clf_dt = tree.DecisionTreeClassifier(min_samples_split=25)
clf_dt.fit(X_train, y_train)
predicts_dt = clf_dt.predict(X_test)
print('Decision tree Accuracy Rate, which is calculated by accuracy_score() is : %f' % accuracy_score(y_test, predicts_dt)) #输出: SVM Accuracy Rate, which is calculated by accuracy_score() is : 0.916000(4)随机森林算法
#Random forest classifier随机森林算法 clf_rf = RandomForestClassifier(n_estimators=10, min_samples_split=2, max_depth=30)
clf_rf.fit(X_train, y_train)
accuracy_rf = clf_rf.score(X_test, y_test)
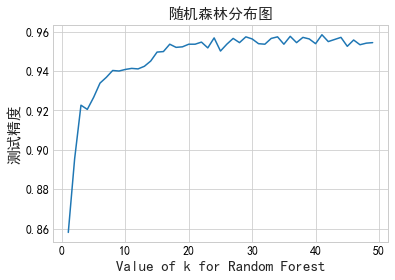
print('Random Forest Accuracy Rate, which is calculated by accuracy_score() is : %f' % accuracy_rf) #输出: Random Forest Accuracy Rate, which is calculated by accuracy_score() is : 0.954133通过以上的计算可以知道到目前为止随机森林算法产生的效果是最好的,所以我们对其进行进一步的优化:
#随机森林算法优化 max_depth = range(1,50)
scores = [] for r in max_depth:
clf_rf = RandomForestClassifier(n_estimators=10, min_samples_split=2, max_depth=r)
clf_rf.fit(X_train,y_train)
y_pred = clf_rf.predict(X_test)
scores.append(accuracy_score(y_test, y_pred)) #我们可以在每次使用不同的值进行计算,但是由图可以发现深度在30左右的时候会有更好的结果 plt.plot(max_depth,scores)
plt.title('随机森林分布图',fontsize=15)
plt.xlabel('Value of k for Random Forest',fontsize=15)
plt.ylabel('测试精度',fontsize=15)
plt.tick_params(labelsize=12, colors = 'black')
(5)神经网络
#neural networks神经网络 from sklearn.neural_network import MLPRegressor
clf_nlpr = MLPRegressor(max_iter=100, learning_rate='adaptive', hidden_layer_sizes=200)
clf_nlpr.fit(X_train, y_train)
predicts_nlpr = clf_nlpr.predict(X_test)
print('MLPR Accuracy Rate, which is calculated by accuracy_score() is : %f' % accuracy_score(y_test, predicts_svm)) #输出: MLPR Accuracy Rate, which is calculated by accuracy_score() is : 0.916000由以上的几种模型可以看出随机森林模型就是一个最好的模型。
现在我们就可以在基于5个相关参数就能够预测谁可能离开公司的模型了
本文内容转载自网络,本着传播与分享的原则,来源/作者信息已在文章顶部表明,版权归原作者所有,如有侵权请联系我们进行删除!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



