

Python培训
400-996-5531
400-996-5531
当完成了网页html的download之后,下一步当然是从网页中解析我们想要的数据了。那如何解析这些网页呢?Python中有许多种操作简单且高效的工具可以协助我们来解析html或者xml,学会这些工具抓取数据是很容易了。
说到爬虫的html/xml解析(现在网页大部分都是html),可使用的方法实在有很多种,如:
正则表达式
BeautifulSoup
Lxml
PyQuery
CSSselector
其实也不止这几种,还有很多,那么到底哪一种最好呢?这个很难说,萝卜白菜各有所爱,这些方法各有特色,只能说选择一款你用着顺手的。博主将会陆续给大家介绍这些好用的解析器,但是本篇从正则表达式开始。
那是不是只要掌握一种就可以了?用不着会那么多吧。确实,熟练掌握一种也可以完成数据的抓取,但随着你解析网页的数量增多,你会发现有时候使用多种方法配合解析网页会更简单,高效,因为这些方法各有特色,不同环境下发挥的作用不一样。因此,建议大家熟练掌握至少两种为佳,这样当你面对复杂结构网页的时候,解析方法会更灵活。
好了,开始我们的解析之旅吧!
正则表达式
--------------------------
正则表达式(regular expression)简称(regex), 是一种处理字符串的强大工具。它作为一种字符串的匹配模式,用于查看指定字符串是否存在于被查找字符串中,替换指定字符串,或是通过匹配模式查找指定字符串。正则表达式在不同的语言里面,语法也基本是相同的,也就是说学会了一种语言的正则,再学习其它的就很快了。
其主要的匹配过程是:
先用正则语法定义一个规则(pattern)
然后用这个规则与你download的网页字符串进行对比,根据pattern提取你想要的数据。
好了,让我们看看Python正则表达式的语法:
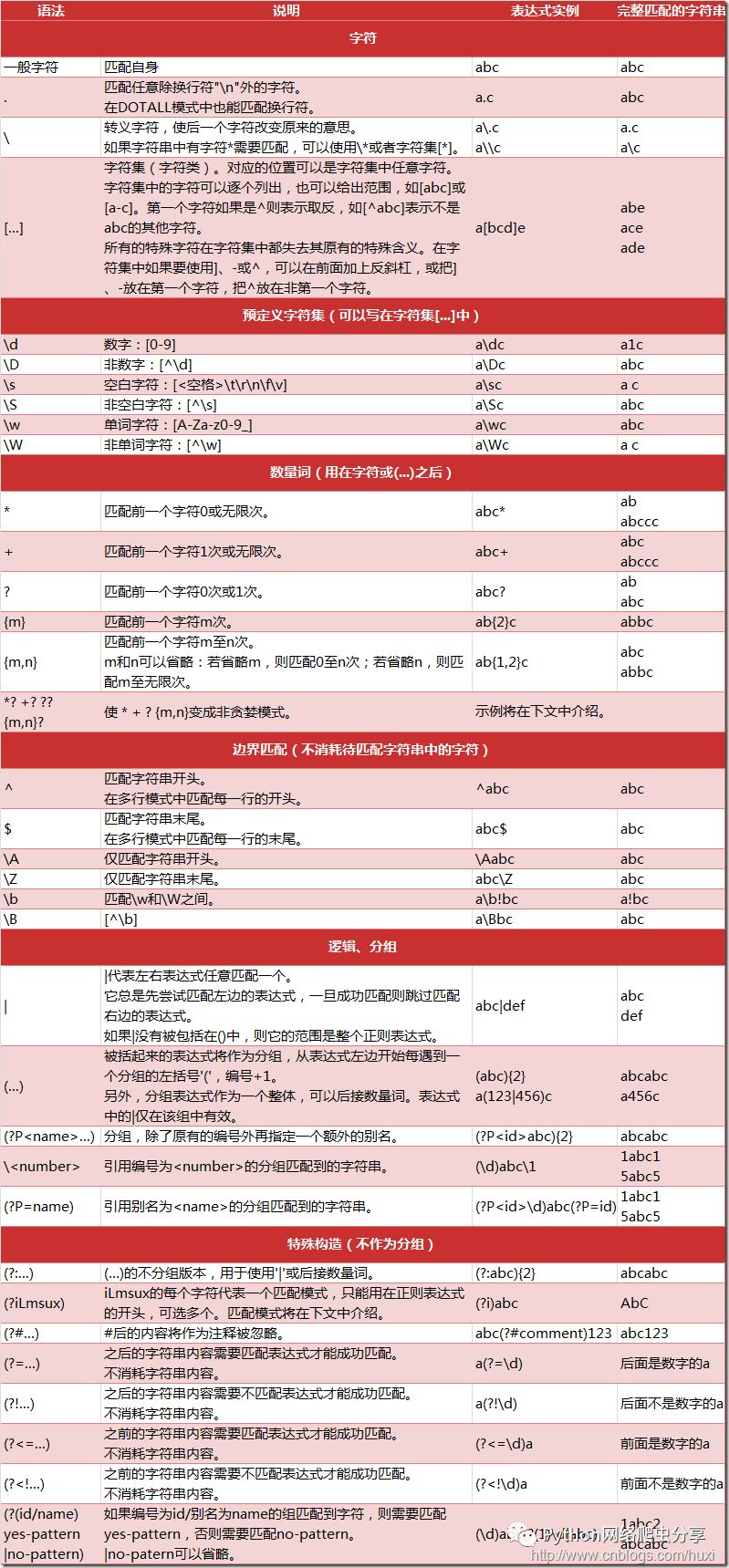
好乱,看不懂!!!
别着急,开始都是这样的(当然会的小伙伴可以直接跳过)。下面看几个例子,你马上就学会了。
--------------------------
你的第一个正则表达式
--------------------------
我们举一个常遇到的一个例子。比如,一个人的邮箱是这样的lixiaomei@qq.com,那么我们如何从一大堆的字符串把它提取出来呢?
根据正则语法,我们可以这样来定义一个pattern:\w+@\w+\.com
为什么这么定义呢?让我们来看看。
"\w" 的意思是单词字符[A-Za-z0-9_]。注意是 "单字符串",可以是A-Z或者a-z或者0-9或者_各国语言中的任意一个。
"+" 匹配前一个字符1次或无限次。那么 "\w+" 组合起来的意思就是匹配一次或无限多次的但字符串[A-Za-z0-9]组合的字符串。
"@" 是邮箱的特定字符,所以固定不变。
第二个 "\w+" 与前一个是一个道理,匹配一次或无限次的[A-Za-z0-9]组合的字符串。
" \. " 的含义是将" . "转义,因为 " . " 本身也是正则语法中的其中一种,为了真的得到 ".com" 而不是带有功能的" . ", 所以在前面加上 "\" 转义字符。
所以,不论是例子中的 lixiaomei@qq.com,还是其它如xiaoxiao@#之类的邮箱,只要符合规则全都可以匹配,怎么样,简单吧!
问题来了,有的邮箱格式可是xiaoxiao@#这样的!这样的话上面的规则就不能用了。没错,上面的规则比较特殊,只能匹配单一格式的邮箱名。那么怎样设计一个满足以上两种格式的pattern呢?看看这个:\w+@(\w+\.)?\w+\.com
这个又是什么意思?
\w+@与之前一样
(\w+\.)?中的“ ? ”是匹配0次或1次括号分组内的匹配内容,"()" 则表示被括内容是一个分组,分组序号从pattern字符串起始往后依次排列。分组的概念非常重要,在后面 “匹配对象方法” 章节会着重介绍其如何使用。
\w+\.com与之前一样
因为是匹配0次或1次,那么就意味着括号内的部分是可有可无的,所以这个pattern就可能匹配两种邮箱格式。
“?”是0次或1次,那么 \w+@(\w+\.)*\w+\.com 模式就更厉害了," * " 可以匹配0次或无限次。
明白了这个之后,相信你应该对正则表达式有一个概念了,但还有很多种语法以及组合方法需要在实践中反复练习。这里只介绍Python中正则表达式比较常见的匹配模式,更多内容可参考《Python核心编程》一书,关注公众号并发送 “学习资料” 便可轻松拿到。
--------------------------
re模块核心函数
--------------------------
上面简单的介绍了正则表达式的pattern是如何设置的,那么下一步我们就可以开始我们的提取工作了。在Python的re模块中有几个核心的函数专门用来进行匹配和查找。
compile()函数
函数定义: compile(pattern, flag=0)
函数描述:编译正则表达式pattern,然后返回一个正则表达式对象。
为什么要对pattern进行编译呢?《Python核心编程 》里面是这样解释的:
使用预编译的代码对象比直接使用字符串要快,因为解释器在执行字符串形式的代码前都必须把字符串编译成代码对象。
同样的概念也适用于正则表达式。在模式匹配发生之前,正则表达式模式必须编译成正则表达式对象。由于正则表达式在执行过程中将进行多次比较操作,因此强烈建议使用预编译。而且,既然正则表达式的编译是必需的,那么使用预编译来提升执行性能无疑是明智之举。re.compile()能够提供此功能。
原来是这样,由于compile的使用很简单,所以将在以下几个匹配查找的函数使用方法中体现。
match()函数
函数定义: match(pattern, string, flag=0)
函数描述:只从字符串的最开始与pattern进行匹配,匹配成功返回匹配对象(只有一个结果),否则返回None。
import res1 = '我12345abcde's2 = '.12345abcde'# pattern字符串前加 “ r ” 表示原生字符串pattern = r'\w.+'# 编译patternpattern_compile = re.compile(pattern)# 对s1和s2分别匹配result1 = re.match(pattern, s1)result2 = re.match(pattern, s2)print(result1)print(result2)>>> <_sre.SRE_Match object; span=(0, 11), match='我12345abcde'>>>> None
注意:
match函数是从最开始匹配的,意思是如果第一个字符就不匹配,那就直接玩完,返回None。
Python中pattern字符串前面的 " r " 代表了原生字符串的意思。
问题来了,为什么result1结果有这么多的东西啊?貌似最后一个才是要匹配的对象。这个要怎么提取出来呀?别着急,我们现在得到的是匹配对象,需要用一定的方法提取,我们后面会在《匹配对象的方法》章节来解决这个问题,继续往下看。
search()函数
函数定义: search(pattern, string, flag=0)
函数描述:与match()工作的方式一样,但是search()不是从最开始匹配的,而是从任意位置查找第一次匹配的内容。如果所有的字串都没有匹配成功,返回None,否则返回匹配对象。
import res1 = '我12345abcde's2 = '+?!@12345abcde'# pattern字符串前加 “ r ” 表示原生字符串pattern = r'\w.+'pattern_compile = re.compile(pattern)result1 = re.search(pattern_compile, s1)result2 = re.search(pattern_compile, s2)print(result1)print(result2)>>> <_sre.SRE_Match object; span=(0, 11), match='我12345abcde'>>>> <_sre.SRE_Match object; span=(4, 14), match='12345abcde'>
可以看到无论字符串最开始是否匹配pattern,只要在字符串中找到匹配的部分就会作为结果返回(注意是第一次匹配的对象)。
findall()函数
函数定义: findall(pattern, string [,flags])
函数描述:查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表
import res1 = '我12345abcde's2 = '+?!@12345abcde@786ty'# pattern字符串前加 “ r ” 表示原生字符串pattern = r'\d+'pattern_compile = re.compile(pattern)result1 = re.match(pattern_compile, s2)result2 = re.search(pattern_compile, s1)result3 = re.findall(pattern_compile, s2)print(result1)print(result2)print(result3)>>> None>>> <_sre.SRE_Match object; span=(1, 6), match='12345'>>>> ['12345', '786']
上面同时列出了match、search、findall三个函数用法。findall与match和search不同的地方是它会返回一个所有无重复匹配的列表。如果没找到匹配部分,就返回一个空列表。
--------------------------
匹配对象的方法
--------------------------
以上re模块函数的返回内容可以分为两种:
返回匹配对象:就是上面如 <_sre.SRE_Match object; span=(0, 5), match='12345'> 这样的对象,可返回匹配对象的函数有match、search、finditer。
返回一个匹配的列表:返回列表的就是 findall。
因此匹配对象的方法只适用match、search、finditer,而不适用与findall。
常用的匹配对象方法有这两个:group、groups、还有几个关于位置的如 start、end、span就在代码里描述了。
group方法
方法定义:group(num=0)
方法描述:返回整个的匹配对象,或者特殊编号的字组
import res1 = '我12345+abcde'# pattern字符串前加 “ r ” 表示原生字符串pattern = r'\w+'pattern_compile = re.compile(pattern)# 返回匹配的字符串result1 = re.match(pattern_compile, s1).group()# 返回匹配开始的位置result2 = re.match(pattern_compile, s1).start() # 返回匹配结束的位置result3 = re.match(pattern_compile, s1).end() # 返回一个元组包含匹配 (开始,结束) 的位置result4 = re.match(pattern_compile, s1).span() print(result1)print(result2)print(result3)print(result4)>>> 我12345>>> 0>>> 6>>> (0, 6)
这样匹配字符串就提取出来了。
import res1 = '我12345+abcde'# pattern字符串前加 “ r ” 表示原生字符串pattern = r'(\w+)\+(\w+)'pattern_compile = re.compile(pattern)# 返回匹配的整个字符串result1 = re.match(pattern_compile, s1).group()# 返回匹配的第一个子组字符串result2 = re.match(pattern_compile, s1).group(1)# 返回匹配的第二个子组字符串result3 = re.match(pattern_compile, s1).group(2)print(result1)print(result2)print(result3)>>> 我12345+abcde>>> 我12345>>> abcde
这里就需要用到我们之前提到的分组概念。
分组的意义在于:我们不仅仅想得到匹配的整个字符串,我们还想得到整个字符串里面的特定子字符串。
如上例中,整个字符串是“我12345+abcde”,但是想得到 “abcde”,我们就可以用括号括起来。因此,你可以对pattern进行任何的分组,提取你想得到的内容。
另外,如果匹配对象时None,那么继续使用匹配对象方法会报错AttributeError,因此也建议使用except异常来处理。
groups方法
方法定义:groups(default =None)
方法描述:返回一个含有所有匹配子组的元组,匹配失败则返回空元组
import res1 = '我12345+abcde'# pattern字符串前加 “ r ” 表示原生字符串pattern = r'(\w+)\+(\w+)'pattern_compile = re.compile(pattern)# 返回含有所有子组的元组result1 = re.search(pattern_compile, s1).groups()print(result1)>>> ('我12345', 'abcde')
--------------------------
re模块的属性
--------------------------
re模块的常用属性有以下几个:
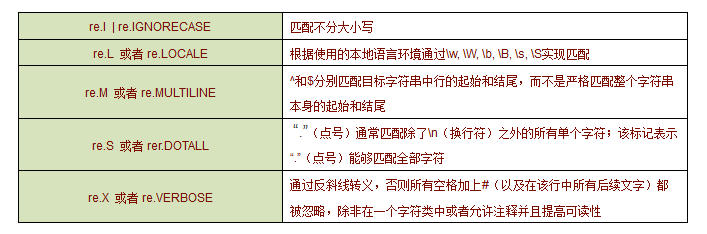
其实re模块的属性就是函数中的flag参数,以第一个大小写flag为例:
import res1 = '我12345+aBCde'# pattern字符串前加 “ r ” 表示原生字符串pattern = r'(\w+)\+(\w+)'pattern_compile = re.compile(pattern, re.IGNORECASE)# 返回一个匹配的列表result1 = re.findall(pattern, s1)print(result1)>>> [('我12345', 'abcde')]
import res1 = '我12345+aBCde'# pattern字符串前加 “ r ” 表示原生字符串pattern = r'(\w+)\+(\w+)'# 返回一个匹配的列表result1 = re.findall(pattern, s1, re.IGNORECASE)print(result1)>>> [('我12345', 'abcde')]
这里注意:
如果我们定义了compile编译,需要将flag填到compile函数中,否则填到匹配函数中会报错
如果没有定义compile,则可以直接在匹配函数findall中填写flag
本篇介绍正则表达式的快速入门方法,关于更多正则表达式的内容可以参考如下链接:
Python官网关于正则表达式的操作:
#/2/library/re.html
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有




