

Python培训
400-996-5531
400-996-5531

前段时间利用周末时间研究网络爬虫和反爬虫技术,然后写了篇文章《网络爬虫和反爬虫技术研究》,顺便简单了解了下Python,这网络爬虫和RPA软件机器人可不是一回事,差别不小,在那篇文章里讲了较多,Python这种编程语言简单易懂,比较适合用来开发网络爬虫。
最近在美国的一位老朋友知道我在研究人工智能应用,特意推荐给我一位美国14岁华裔女孩杨君熙(Emma Yang)的手机AppTimeless(永恒)众筹项目。在网上查了些资料,真是不看不知道,看了只有“佩服”儿子,向这位00后女孩学习!(参见前两天专门写的一篇文章《众筹项目手机App Timeless(永恒)背后的故事》)
仔细想想,这位00后的杨小姐这么了不起,一方面的而且确是她自己天才+努力,一方面也和她的父母从小时候对她的教育分不开,杨小姐在6岁就开始接触编程,6岁!?不禁想到我6岁在做什么?爬树?掏鸟蛋?玩泥巴?再看看我们家那位00后小朋友,6岁好像最喜欢看动画片!真是别人家的孩子不能比!也不用比!我们努力赶上来!
这个周末从项目组借了Python的书回来,就是专门和我家这位00后一起学习这门语言。从哪里开始呢?Python适合开发网络爬虫,就从一个简单的网络爬虫开始!
我家这位00后最喜欢音乐,经常在写作业之余偷偷带上耳机听音乐,因此,我们决定用网络爬虫去“扒”百度音乐里的好听音乐!这就是我们这个周末的目标!
互联网行业发展到现在这个阶段,网络上太多的信息,有用的,没用的,不能有效利用信息就等于没有信息,由此学习网络爬虫的人越来越多,一方面,互联网可以获取的有价值的数据越来越多,而另一方面,像 Python这样的编程语言使网络爬虫开发变得非常简单、容易上手。
利用网络爬虫我们可以获取大量的价值数据,从而获得感性认识不能得到的信息,在以下场景种网络爬虫作用非常大:
(一)爬取数据,进行市场调研和商业分析
知乎:爬取优质答案,并筛选出各个话题下最有价值的内容。
淘宝、京东:爬取商品、评论及销量数据,并在此数据基础上对各种商品及用户的消费场景进行分析。
链家:爬取房产买卖及租售信息,分析房价变化趋势、然后做不同区域的房价分析。
智联:爬取各类职位信息,然后分析各行业人才需求情况及薪资水平。
雪球网:爬取雪球高回报用户的行为,对股票进行分析和预测。
(二)作为机器学习、数据挖掘的原始数据
机器学习,抓取更多维度的数据,便于做出更好的模型。
图像识别,抓取网络上的大量的图片作为训练集进行训练,提高图像识别的精度。
(三)爬取优质的资源:图片、文本、视频
爬取知乎等图片网站,获得各种图片,然后怎么想怎么用就看自己的需要了。
爬取微信公众号文章,分析新媒体内容运营策略!
在没有网络爬虫的情况下,我们只能手动来完成这个大量重复而有枯燥简单的复制粘贴操作,这个就是“人肉爬虫”了!非常浪费人力,假如想要爬下来100万行的数据,“人肉爬虫”需要两年废寝忘食的工作!而高性能的网络爬虫在一天之内就能完成!而且,不需要任何人为干预!
对于很多人而言,或者会认为网络爬虫的技术很是复杂,技术要求很高,用Python来开发一个网络爬虫可能需要精通Python,需要掌握Python各个知识点!但是,其实不然,我学习一门新的编程语言的经验就是,翻翻书,直接开干,做完一个项目,啥也会了!亲自实践过,做个伪专家还是可以的。
在开始开发网络爬虫之前,首先要熟悉一下Python编程的套路,打开Python3.6.4安装后自带的demo:
学完这些Python自带的demo后,基本就掌握了Python编程的基础,能够看懂并写一些Python程序了。
但是就这样用Python开发一个网络爬虫来爬百度音乐里的哪些好听的音乐还不够,这需要掌握正确的程序设计方法和一些网络爬虫基础知识,正好上个周末才研究了网络爬虫和反爬虫技术,懂得这些爬虫的工作原理,简单总结一下:
第一、了解网络爬虫的基本工作原理
网络爬虫基本上都是按“发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来工作,而这其实也是模拟了我们使用浏览器获取网页信息的过程。简单来说,我们向服务器发送请求后,会得到返回的页面,通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。
在这部分需要了解 HTTP 协议及网页基础知识,POST\GET,HTML,CSS,JS等,对于开发网络爬虫而言,简单了解就可以,不需要什么系统学习。
第二、学习 Python 包并实现基本的爬虫过程
查看了一下Python的技术资料,发现和爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,建议从requests+Xpath开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。而如果使用BeautifulSoup,就会发现这比Xpath 要省事不少,一层一层检查元素代码的工作全都省略了。
掌握这些之后,就会发现其实网络爬虫的基本套路都差不多,静态网站根本不在话下,小猪、豆瓣、糗事百科、腾讯新闻等差不多可以上手搞定了。
当然了,如果需要爬取异步加载的网站,就还要继续学习浏览器抓包分析真实请求或者学习SeleniumWeb Driver来实现,这样,知乎、时光网这些动态的网站也就基本没问题了。因为这两年在工作中我对于RPA技术研究较多,Selenium技术不在话下!
在这个过程中需要了解一些Python的基础知识,这些在Python自带的demo里都有涉及:
文件读写:用来读取参数、保存爬下来的内容
list(列表)、dict(字典):用来序列化爬取的数据
条件判断( if/else ):解决爬虫中的判断是否执行
循环和迭代( for ……while ):用来循环爬虫步骤
第三、了解非结构化数据的存储
网络爬虫爬回来的数据可以直接用文档形式存在本地,也可以存入数据库中。在数据量不大的时候,可以直接通过 Python 的语法或 pandas 的方法将数据存为csv这样的文件。当然,可能爬回来的数据并不是干净的,会有缺失、错误等等,这就还需要对数据进行清洗,可以学习 pandas 包的基本用法来做数据的预处理,从而得到更干净的数据。
第四、学习 scrapy并搭建工程化的爬虫
在掌握了前面讲到的这些技术后,开发针对一般量级和复杂程度数据的网络爬虫就基本没有问题了,但是在遇到非常复杂的情况,仍然会力不从心,这个时候,强大的 scrapy 框架就非常有用了。scrapy 是一个功能非常强大的网络爬虫框架,不仅能便捷地构建request,还有强大的 selector 能够方便地解析 response,然而最让人惊喜的还是其超高的性能,由此可以将网络爬虫工程化、模块化,学会 scrapy后,就可以自己去搭建一些爬虫框架,成为了一个合适的网络爬虫工程师了。
安装scrapy框架很简单,运行命令行就可以(“pip install Scrapy ”)。
第五、学习数据库基础以应对大规模数据存储
在网络爬虫爬回来的数据量小的时候,可以用文档的形式来存储,一旦数据量大了,这就有点行不通了,所以掌握一种数据库是必须的,学习目前比较主流的 MongoDB 就OK。MongoDB 可以很方便地用来存储一些非结构化的数据,比如各种评论的文本,图片的链接等等,当然了,也可以利用PyMongo这个组件更方便地在Python中操作MongoDB。
开发网络爬虫,其实用到的数据库知识非常简单,主要是数据如何入库、如何进行提取。对于我而言,这个完全不是问题,我刚毕业就做了两年Oracle DBA,后来在工作前十年一直都是数据库设计专家。
第六、掌握各种技巧来应对特殊网站的反爬措施
当然,开发网络爬虫过程中也会经历一些重大打击,例如被网站封IP、比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。遇到这些网站平台的反爬虫手段,就需要一些高级的技巧来应对,常规的比如访问频率控制、使用代理IP池、抓包、验证码的OCR处理等等。往往网站在高效开发和反爬虫之间会偏向于前者,而这也为网络爬虫提供了闪展腾挪的空间,掌握这些应对反爬虫的技巧,绝大部分的网站还是可以搞定的。
第七、开发分布式网络爬虫实现大规模并发采集
开发一个网络爬虫爬取基本数据已经不是问题了,但是这里有一个效率问题,在爬去海量数据的时候,网络爬虫的运行效率就是设计和构架的一个关键点,而用以解决这个问题的就是“分布式网络爬虫”。
在计算机技术上,“分布式”这个概念很是高大上,最近很火的区块链的本质就是“分布式的账本系统”,但是透过现象看本质,分布式网络爬虫其实就是利用多线程的原理让多个网络爬虫同时工作,需要掌握 Scrapy +MongoDB + Redis 这三种工具。Scrapy 前面简单介绍过来,主要用于做基本的页面爬取,MongoDB 用于存储爬取的数据,而Redis 则用来存储要爬取的网页队列,也就是任务队列。所以有些概念听起来很吓人,但其实分解开来看,也不过如此。当能够写分布式网络爬虫的时候,那么接下去就可以尝试打造一些基本的网络爬虫架构来实现一些更加自动化的数据获取。
简单演示一下百度音乐网络爬虫的运行:
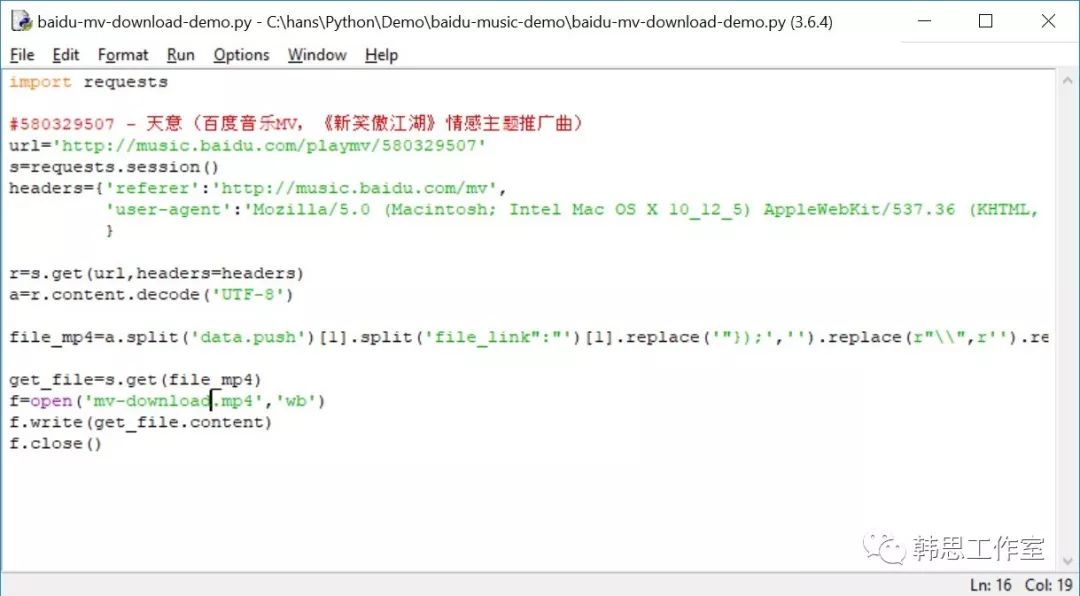
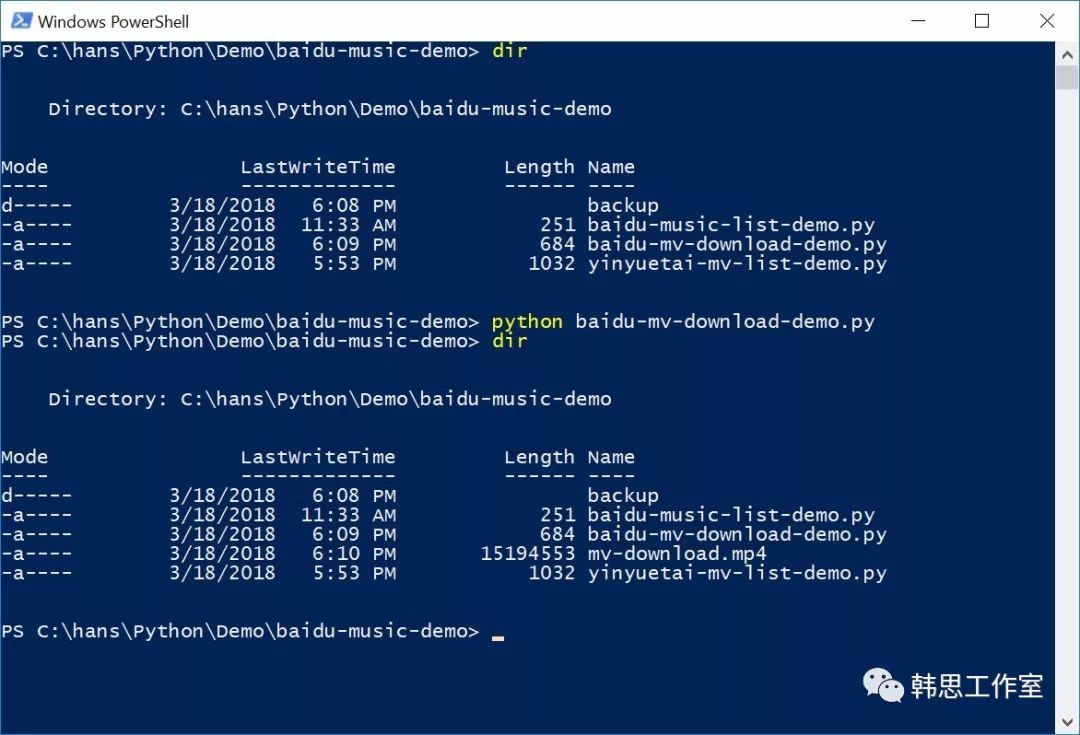
从百度音乐直接下载MV没有问题了,很快发现很多非常酷的音乐不在百度音乐储存着,而是从音悦台分享过来的,怎么从音悦台下载喜欢的音乐文件呢?打开页面分析了一下HTML,CSS,JavaScript,重新写了一个python脚本,搞定!这就可以用Python来下载音悦台的高清MV了。
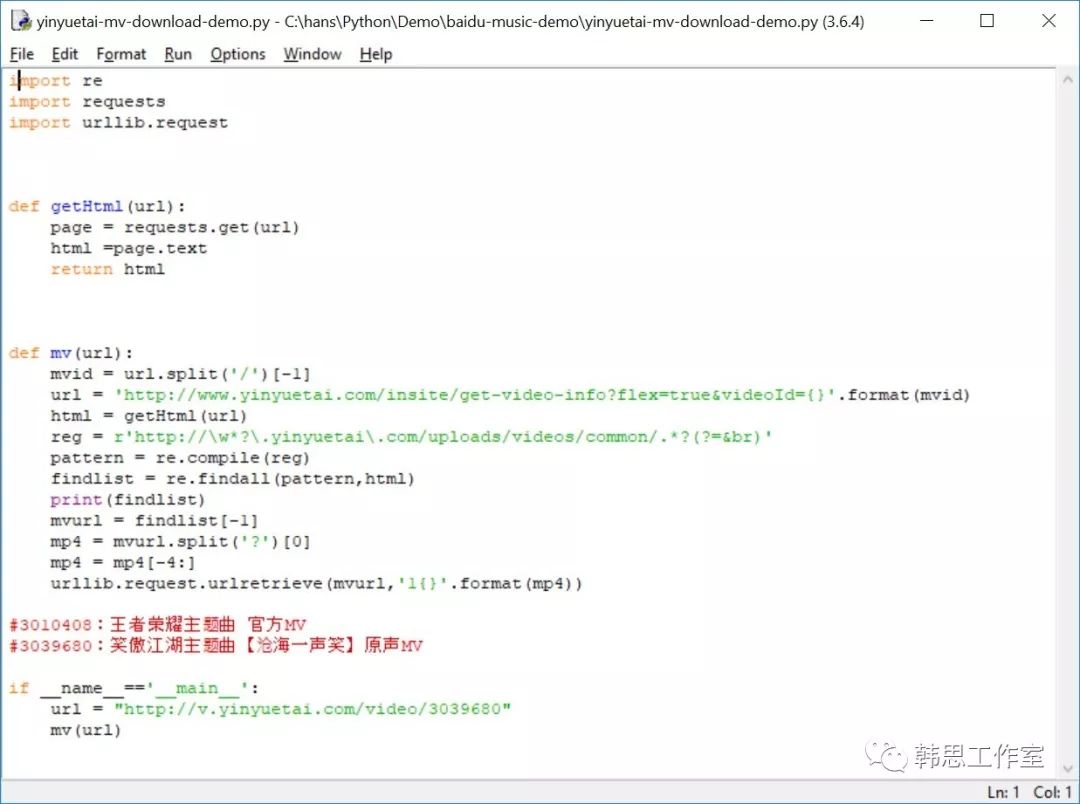
现在,我们家的这位00后可以使用Python开发的网络爬虫来爬到他喜欢的各种最新流行音乐了,就算是将百度音乐和音悦台所有的MV都给爬下来也不是问题!“王者荣耀主题曲”?不行!不行!我不答应!写作业去!写作文去!复习功课去!预习功课去!小子,还治不了你…等我把来把黄沾先生作词作曲的“沧海一声笑”爬下来!欣赏ing...
简单总结一下,学习用Python来开发网络爬虫,不要系统地去啃书本,而是要找一个实际项目做一做,例如这个周末我和儿子尝试着做的百度音乐网络爬虫,简单学习一下就开始干,遇到问题上网查一下解决问题,问题都解决了,网络爬虫开发出来调试通过可以运行了,然后此时总结,这个时候基本上一般地网络爬虫都可以开发了。
学习网络爬虫技术,不需要系统的精通一门语言,也不需要特别高深的数据库技术,最高效的学习途径就是从实际的项目中去学习这些零散的知识点,东成西就,然后搞定!
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有




